However, this cannot be used in any of the following situations:
· Outside of a declaration section
· Within the declaration section of a nested block (a block within a block)
· In a package specification
· In a package body outside of a procedure or function definition
· In a type body outside of a method definition
Begin ... end; – autonomous transaction starts from the begin of the block, where the defining statement is found. The corresponding end does not close the autonomous transaction.
commit; (or rollback;) – data changes made in an autonomous transaction must be committed or rolled back. If such activity has not happened and the block defined as an autonomous transaction is ended, the Oracle RDBMS will rollback the entire transaction and raise the following message “ORA-06519: active autonomous transaction detected and rolled back.”
An autonomous transaction allows you to do the following:
· Leave the context of the calling transaction (parent)
· Perform SQL operations
· Commit or rollback those operations
· Return to the calling transaction's context
· Continue with the parent transaction
II. Basic Example
Although this task is very simple using autonomous transactions, it is possible to solve the problem without this concept.
This example uses the tables EMP and AUDIT_EMP with the following structures:
|
Create table emp (empno number primary key, ename varchar2(2000), deptno number, mgr number, job varchar2(255), sal number) |
create table Audit_emp (action_nr number, action_cd varchar2(2000), descr_tx varchar2(2000), user_cd varchar2(2000), date_dt date) |
The goal is to only track salary. Therefore a BEFORE UPDATE trigger is placed on the column Sal. There is also a generic function to log activities, which will be used for different examples later)
|
create or replace trigger Bu_emp before update of sal on Emp
1 2
f_log_audit (user, 'update', 'update of emp.salary',
3
4 |
create or replace procedure f_log_audit ( who varchar2, what varchar2, descr_tx varchar2, when_dt date) is pragma autonomous_transaction; begin insert into Audit_emp values(audit_seq.nextval, what, descr_tx, who, when_dt); commit; end; |


The code works in 4 steps:
1. The trigger calls the function F_LOG_AUDIT. (still in the same transaction)
2. The declaration block of the function still belongs to the main transaction; however, the RBMS found the line PRAGMA AUTONOMOUS_TRANSACTION. This means that from the following BEGIN, it should start a new transaction in the current session.
3. Inside of the autonomous transaction, a new record was inserted into the table AUDIT_EMP and the change was committed. Note that the commit happened only for changes in this transaction. It is completely independent from the parent one. Any unsaved data will be still unsaved. Also, it does not matter what happens with the update statement. The log information was already sent to the database. Nothing in the parent transaction removes the record. The key point to remember is that commit/rollback statements in autonomous transactions are absolutely independent from ones in other transactions. They only affect changes in the specified transaction, not in all others.
4. When the autonomous transaction ends, since the insert has been committed, the RDBMS can properly return back to main transaction – to our trigger, from which the procedure have been called.
This advanced transaction control feature has tremendous power. The next section will discuss these transactions in more depth.
III. Nested vs. Autonomous Transactions
To be able to properly describe an autonomous transaction, it is useful to make a comparison to a more familiar concept, namely, nested transactions. As defined in "Nested Transactions: An Approach to Reliable Distributed Computing" by J. Moss at M.I.T, a nested transaction is “a tree of transactions, the sub-trees of which are either nested or flat transactions.”
For Oracle professionals this means that each time a function, procedure, method or anonymous block is called within another block or trigger, it spawns a sub-transaction of the main transaction. Everything in this list (except anonymous sub-blocks) can be defined as an autonomous transaction. What are the differences between the two definitions? To answer this, it is necessary to define the term “scope” as “the ability to see values of various things within the database.” Scope can be applied to any of the following:
· Variables
· Session settings/parameters
· Data changes
· Locks
· Exceptions
Each test case will be defined by the object of interest and summarized by the rule.
A. Locks
This is a simple problem. In the parent transaction, the row from the EMP table is locked for update. Exactly the same procedure is done in LOCK_TEST. Locks are a good example of transactional resources. This test shows how autonomous transactions work with them.
|
declare v varchar2(2000); begin select ename
from emp where ename = SCOTT' for update;
commit; End; |
Nested |
procedure lock_test is v varchar2(2000); begin select ename into v from emp where ename = 'SCOTT' for update; end; |
|
Autonomous |
procedure lock_test is v varchar2(2000); pragma autonomous_transaction; begin select ename into v from emp where ename = 'SCOTT' for update; commit; end; |

These results are extremely interesting. The first (nested) version of the procedure worked without question. But in the second case, the result was: “ORA-00060: deadlock detected while waiting for resource”. This leads to the following conclusion:
Rule #1: An autonomous transaction does not share transactional resources (such as locks) with the main transaction.
B. Session Resources
Since transactional resources are processed differently in autonomous transactions in comparison to nested ones, it does make sense to test session-level resources in the same context. The most widely used resources (packaged variables) have been used for this purpose. .. The test attempted to update the variable from both sides. In the procedure defined as an autonomous transaction, the value of variable VAR_TEST.GLOBAL_NR (already changed in the parent transaction) is displayed first. Next, the variable is updated and after ending the autonomous transaction, the value from the parent will be checked.
|
Begin
1 dbms_output.put_line var_test.global_nr );
2 var_test.global_nr := 10
p_var_test (20);
3 var_test.global_nr ); End; |
package var_test
1 global_nr number :=0; end; |
||||||||||||
|
procedure p_var_test pragma autonomous_transaction;
2 dbms_output.put_line( var_test.global_nr );
3 var_test.global_tx := v_nr; commit; end; |
There are three places, where values are assigned (yellow) and three places, where values are displayed (blue). The output screen showed the following:
Start values: 0
Before Auto value: 10
After Auto values: 20
The first value is different from second– the autonomous transaction can see the change made by the parent one. The second value is different from the third – the parent transaction can see the change made by the child one. This works in the expected way.
Rule #2: Autonomous transactions and main transactions belong to the same session and share the same session resources.
C. Changes in Parent Transactions
So far, the sections above discussed uncommitted changes in autonomous transactions. At this point, a logical question to ask is: What would happen with uncommitted changes in the parent transaction? This can be answered using the following test:
· In an anonymous block, count the records from the table AUDIT_EMP (it is empty for now).
· Insert a new record into that table without a commit and call the procedure DATA_CHANGE_TEST, which will try to count the records in the same table.
|
Declare v_nr number;
Select count(1) into v_nr from audit_emp; insert into audit_emp ‘Test’,sysdate); dbms_output.put_line
data_change_test; End; |
Nested |
procedure data_change_test is v_nr number; begin select count(1) into v_nr from audit_emp dbms_output.put_line (‘Count#2=‘||v_nr); end; |
|
Autonomous |
procedure data_change_test is v_nr number; pragma begin select count(1) into v_nr from audit_emp dbms_output.put_line (‘Count#2=‘||v_nr); end; |

The results are as follows:
Nested transaction:
Count#1:0
Count#2:1
Autonomous
Count#1:0
Count#2:0
In this case, the autonomous transaction does not recognize the new record. It simply doesn’t exist for it leading to the following conclusion:
Rule#3: Non-committed changes of parent transactions are not immediately visible to autonomous transactions, but are visible for nested ones.
D. Changes in Child Transactions
The test described in the previous section indicated what happens with records that have been inserted from the parent transaction. What are the changes going to be in the child transactions? To answer this question, some additional definitions are needed:
Isolation level is defined as the degree to which the intermediate state of the data being modified by a transaction is visible to other concurrent transactions; and, the data being modified by other transactions is visible to it. There are two supported levels in Oracle 8i/9i (other database manufacturers may have different isolation levels):
· Read committed: a transaction rereads data that it has previously read and finds that another committed transaction has modified or deleted the data. A transaction re-executes a query, returning a set of rows that satisfies a search condition and finds that another committed transaction has inserted additional rows that satisfy the condition
· Serializable: the transaction cannot see any changes that happened in other transactions, that have been processed AFTER it started
It is clear that this parameter does not have any connection with nested transactions. They are parts of main one and that’s why changes, made in it, have to be visible throughout the whole tree. But for autonomous transactions there is the question – should be any difference with data visibility depending on isolation level? Let’s test it using old pattern – one insert is done in parent transaction and one – in autonomous. Before each test table AUDIT_EMP is truncated.
|
declare v_nr number; Begin set transaction isolation level read committed;
insert into audit_emp values (1,'Test','Test', user,sysdate ); commit_test;
select count(1) into v_nr from audit_emp; dbms_output.put_line (‘Count='||v_nr); end; |
Read committed |
procedure commit_test is pragma autonomous_transaction; begin insert into audit_emp values (1,'Test','Test', user,sysdate ); commit; end; |
|
declare v_nr number; Begin set transaction isolation level serializable;
insert into audit_emp values (1,'Test','Test', user,sysdate ); commit_test;
select count(1) into v_nr from audit_emp; dbms_output.put_line (‘Count='||v_nr); end; |
Serializable |
Results are not the same, as expected:
Read committed:
Count=2
Serializable
Count=1
From these results, it seems that for the Oracle RDBMS, there is no difference between autonomous transaction and transactions from another session in the context of data visibility. This leads to the following conclusion:
Rule#4: Changes made by autonomous transactions may or may not be visible to the parent one depending upon the isolation level, while changes made by nested transactions are always visible to the parent one.
E. Exceptions
As mentioned previously, if changes in the autonomous transaction are not committed or rolled back when it has already ended, the Oracle RDBMS will raise an error and rollback the whole transaction. It is possible that something in the autonomous transaction went wrong. What would happen with uncommitted changes? To test this, the procedure ROLLBACK_TEST was created. There are two insert statements. The second one tried to place text data in a numeric field. In the parent transaction, an exception handler catches the raised exception and counts the number of records that went to the table AUDIT_EMP (as usual, the table is truncated before the test)
|
Declare v_nr number; Begin
Exception when others then select count(1) into v_nr from audit_emp;
dbms_output.put_line (‘Count=‘||v_nr); end; |
Nested |
procedure rollback_test is begin insert into audit_emp value (1,'Test','Test', user,sysdate ); insert into audit_emp value (‘Wrong Data’,'Test', 'Test', user,sysdate ); end; |
|
Autonomous |
procedure rollback_test is pragma autonomous_transaction; begin insert into audit_emp value (1,'Test','Test', user,sysdate ); insert into audit_emp value (‘Wrong Data’,'Test', 'Test', user,sysdate ); commit; end; |

The results are also different
Nested:
Count=1
Autonomous
Count=0
In the second case, both records were lost. This leads to the next rule:
Rule #5: Exceptions raised in an autonomous transaction cause a transaction-level rollback, not a statement-level rollback.
Summary
The first part of this article attempted to explain the differences between nested transactions and autonomous transactions with the goal of clarifying what autonomous transactions are. Using a set of rules, all results should be absolutely predictable. There is no place for surprises in the database development. It is important when working with autonomous transactions to understand how the Oracle RDBMS processes them in the following contexts:
· Transactional resources
· Session-level resources
· Data changes of parent transaction
· Data changes of autonomous transaction
· Exceptions
IV. How to use autonomous transactions
The following are some basic examples covering autonomous transactions that might be found in many reference books. The purpose is to provide a pattern of thinking about autonomous transactions and use some common real world situations so that the suggestions will be applicable.
There are three major areas where autonomous transactions could be helpful:
1. Security Subsystems: Since this feature allows working independently with multiple sets of data, it is relevant for security subsystems
2. Advanced control of transaction level resources allows some structural optimization
3. Resolving non-standard PL/SQL problems
A. Security: Query Audit
The current trend towards more robust security has also influenced the database development industry. This section will discuss how to implement some security using autonomous transactions.
Business Rule: Each request by a user to view the Salary column
should be recorded.
|
Create or replace view v_emp As Select empno, From emp |
package body audit as function record (v_nr number, v_tx varchar2, v_value_nr number) return number is pragma autonomous_transaction; begin insert into audit_emp value (audit_seq.nextval, 'VIEW', ‘Request of ’||v_tx||’=’ ||v_value_nr|| ‘ from emp by pk=’ ||v_nr, user, sysdate ); commit; return v_value_nr; end; End; |
|
|
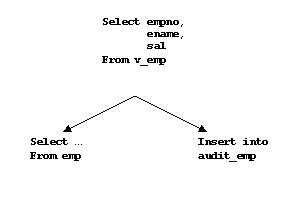
The idea is very simple. There is a view V_EMP, that has exactly the same columns, as the table EMP. But for the column Sal, the packaged function AUDIT.RECORD is used. The function has the value of the column Sal as an incoming parameter so that it can be returned properly. The user will see the value he/she wanted. But, at the same time, this function logs a querying request to the table AUDIT_EMP. This log record is committed at the moment when the user retrieves his data, just as it was specified.
Advanced query audit
In the previous example a fairly interesting technique was used, namely, sending the value of a column to a function to be returned. This trick is used to solve the next problem.
Business Rule:
A user can query specific data only once per session from the temporary dataset that is created each time a session starts.
|
Create or replace view v_emp As Select empno, From temp_emp |
package body clean as function record return number is pragma autonomous_transaction;
begin delete from temp_emp where empno = v_id;
commit; return v_nr; end; End; |
|
|
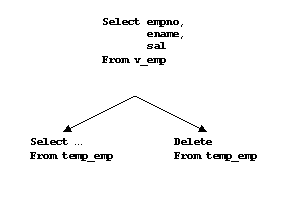
Although is may appear to be a strange concept, the solution is based on the set of assumptions that at the moment of execution of the CLEAN.RECORD command, all data is already cached and available for querying. A this point, it will not interrupt the executed statement. The function CLEAN.RECORD has two parameters: the primary key of the table EMP and value of the column SAL. As in the first example, SAL is needed only to be returned (as temporary storage), while the primary key is used to delete the record from table TEMP_EMP. The algorithm is clear. A selection from the view causes the return of the data from the requested record in addition to removing all records that have been requested. It absolutely satisfies the specified business rule and the problem is solved.
B. Activity Audit
The problem of performing a generic audit was discussed earlier in the very first autonomous transaction example In addition, there are some other interesting tricks that can be used involving autonomous transactions.
Business Rules to be implemented:
A user-executed update on any salary should be recorded, even if the update failed. A user can update Salary only if he/she and his/her direct manager both have the job ‘MANAGER’
The second part of the rule is more complex since it is based on the same table, which is updated. The job of the manager is not known, only the ID. But since Oracle does not allowing it (ORA-04091: table SCOTT.EMP is a mutating, trigger/function may not see it), there is no way to implement the specified rule in conventional trigger.
|
Trigger emp_audit Before update on emp For each row Declare pragma autonomous_transaction; Begin if (check_privileges (:new.mgr,:new.empno,:new.job)) then f_log_audit (user, 'update: rule succeeded', 'update of emp.salary', sysdate); commit; else f_log_audit (user, 'update: rule failed', 'update of emp.salary’, sysdate); commit; raise_application_error (-2001, ‘Access denied!’); end if; End; |
Function check_privileges v_empno number, v_job_emp varchar2) Return boolean is v_job_mgr varchar2(2000); Begin select job into v_job_mgr from emp where empno = v_mgr; if v_job_emp = ‘MANAGER’ and v_job_mgr = ‘MANAGER’ then return TRUE; else return TRUE; end if; End; |
The generic function CHECK_PRIVILEGES is used in many different places. It cannot be modified. But since the trigger is defined as an autonomous transaction, all nested transactions spawned by it are members of the one started in the trigger. Therefore, they are inherently autonomous for the main transaction (in which the update happened). This avoids the Oracle exception and places the business rule as specified.
C. Modular code: Consistency of environment
The Oracle RDBMS sometimes has a set of implicit activities that cannot be separated. For example, any DDL statement forces a commit for the whole transaction. But there are some cases, when this feature does not allow us to do our jobs. Autonomous transactions can provide a back door.
Business Rule:
Committing changes in a subroutine should not force any activity in other routines.
This problem is reasonably common. For example, in a large migration, parts of it are tables A and B. Table B is a child of A, but the foreign key is deferred. Because of other data, table B must be migrated before table A. Before migration of the table B, a script has to generate brand new copy of the future table A (from a database link) with the current day in the table name.
|
Create table A Create table B (a number, b number); Alter table B add constraint a_fk foreign key (a) references A(a) deferrable initially deferred; |
Procedure copy_link_a (v_dt date) Is pragma autonomous_transaction; Begin execute immediate ‘create table a_copy_’ ||to_char (sysdate,’ddmmyyyy’) ||’ as select * from a@link’;
End; |
|
Begin populate_b; copy_link_a (sysdate); populate_a; End; |
This may look simple, but without autonomous transactions it would not be possible since the foreign key is deferred. The creation of the table would force a commit before table A has been migrated. The procedure copy_link_a is autonomous and does not do anything in the main transaction. Thus the business rule can be implemented.
D. Modular code: Structural optimization
The last example can be examined in more detail. It is now possible to separate the migration of two different flows and to be able to switch between them. What is one of the most critical problems in migration? Rollback segments. This is a transaction level property so it could be modified independently. This means that the same session now is allowed to have multiple rollback segments while they are in independent (autonomous) transactions.
Business Rule
Complex batch process can be divided to prevent rollback segment failure.
|
Create table A Create table B (a number, b number); Alter table B add constraint a_fk foreign key (a) references A(a) deferrable initially deferred; |
Procedure copy_link_a (v_dt date) Is pragma autonomous_transaction; Begin set transaction use rollback segment RBS2; large_migration_a (v_dt);
commit; End; |
|
Begin set transaction use rollback segment RBS1; populate_b; copy_link_a (sysdate); populate_a; End; |
This feature allows using different rollback segments for different purposes in parallel mode. It may help to work with mixed data that requires specified settings. Now DBAs do not need to switch major transactions or even the whole session. Rollback segments can be defined by tasks.
E. Non-standard PL/SQL: DDL in triggers
The problem of DDL in triggers is a subset of commit statements in triggers that are allowed in autonomous transactions. But the following case is extremely useful. For example, there is a need to implement real-time communication between a data modeling front-end and an Oracle repository through the view, which displays all attributes of existing objects (physically implemented as columns of tables).
Business Rule
The insertion of a record in the view creates the new column in the specified table.
|
trigger u_uml_attrib Instead of Insert on uml_attrib For each row Declare pragma autonomous_transaction; Begin if check(:new.attrib_cd)=‘Y’ then execute immediate ‘ alter table ’||:new.class_cd ||‘ add column ’||:new.attrib_cd ||‘ ’||:new.datatype; end if; End; |
F. Non-standard PL/SQL: SELECT-only environment
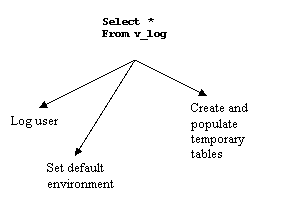
Another simple example, regarding security settings occurs when users have been allowed to only select data from the database (only reporting utilities). However, there is also a need to execute a set of procedures at user logon. The solution is clear, namely, create a view that will call a function with all logon procedures, and query this view in each report at the very beginning. Since the function is defined as an autonomous transaction, all log values are already committed.
Business Rule
The system needs to register a user while the tools allow only SELECT statements.
|
Create or replace view v_log As Select start_session From dual |
function start_session return varchar2 is pragma autonomous_transaction; Begin log_user (user, sysdate); set_system_defaults; populate_temp(sysdate, user); commit; return ‘Y’ Exception when others return ‘N’; End; |
|
|
G. Non-standard PL/SQL: Self-mutation
This paper has already discussed how triggers defined as autonomous transaction allow querying of the same table that the trigger created. This situation can be extended farther.
Business Rule
The Rule for UPDATE is based on the same column that is updated: “The Average salary of an employee cannot be less than half of the maximum salary in his/her department.”
The following example was analyzed in depth in Tom Kyte’s book Expert: One on One Oracle (Wrox Press, 2001) to show when autonomous transactions are not always the proper solution. However, it was a challenge to resolve even this problem using the conventions defined in the book.
The problem only appears simple. The salary could be updated for one employee only or for the set of employees. In the first case, row-level triggers could capture old and new values. Since all other data is static, the trigger could be defined as an autonomous transaction, query the maximum and average salaries in the department of the employee, and correct these aggregate values on the change which happened in the current update.
For the set of rows, the problem rests in the nature of row-level triggers. Only the current update is known but it is not possible to detect the generic influence of the whole statement on aggregates. Statement-level triggers do not have the ability to detect old and new values. If the AFTER-UPDATE trigger is defined as an autonomous transaction nothing will be visible because the changes have not yet been committed in the parent transaction.
|
create type emp_t as object old_sal number, new_sal number);
create type emp_tt as table of emp_t; create package obj as emp_temp emp_tt := emp_tt() end; |
Create or replace trigger AU_EMP After update on EMP pragma autonomous_transaction; cursor cDept is select t.deptno, sum(t.new_sal) -
sum(t.old_sal) DeptDif, from table( cast(obj.emp_temp as emp_tt) ) t group by t.deptno; v_max number; v_avg number; v_count number; Begin for cD in cDept loop select max(sal), avg(sal),count(1) into v_max, v_avg, v_count from emp where deptno =
cd.Deptno; if (greatest (v_max, cd.MaxDif)/2) > ((v_avg*v_count + cd.DeptDif)/v_count) then
raise_application_error end if; end loop; End; |
|
Create or replace trigger BU_EMP before update on EMP begin obj.emp_temp.delete; end; Create or replace trigger BU_EMP_ROW before update on EMP for each row Begin obj.emp_temp.extend; obj.emp_temp(obj.emp_temp.last) := emp_t
(:new.empno, :new.sal); End; |
This solution is based on another new Oracle feature, introduced in version 8.1.5, namely, object collections. Collection EMP_TEMP is instantiated inside of the package. For this reason, it is consistent and accessible for any transaction inside of the session. EMP_TEMP works as a buffer for changes, is populated at the row-level BEFORE-UPDATE trigger, and processed in the AFTER-UPDATE statement level trigger. Only the last trigger is defined as an autonomous transaction. It is necessary to query the state of the table EMP at the very beginning of the update. There is now enough information to validate the rule, namely preexisting data and all modifications. It does not matter how many records have been involved. The algorithm is 100% generic. The error raised in the AFTER-UPDATE trigger will be sent to the main transaction. This means that the update statement will be rolled back, if the checking fails.
H. Oracle 9i Feature: Autonomous transactions in distributed environment
Autonomous transactions were introduced in Oracle 8.1.5. There have been no changes in its definitions up to the current version (Oracle 9.2.0). There is one exception. In Oracle 9i, autonomous transactions could be fired through database links. Previously, it was prohibited to run procedures/functions/triggers defined as autonomous transactions remotely. Now this restriction has been removed.
Business Rule
User needs to execute a remote procedure with an autonomous transaction clause.
|
Begin f_log_audit@ora_sec (user, 'update', 'update of emp.salary', sysdate); update emp set sal = sal*1.5; End; |
create or replace procedure f_log_audit (who varchar2, what varchar2, descr_tx varchar2, when_dt date) is pragma autonomous_transaction; begin insert into Audit_emp values(audit_seq.nextval, what, descr_tx, who, when_dt); commit; end; |
|
Create database connect to scott identified by tiger using “ora_sec” |
Conclusions
The title “Fire and Forget” refers to famous missile systems. They have a lot in common with autonomous transactions. Both can be used easily – one line to code or one button to press. But internally, they are extremely complicated. From a developer’s point of view, they must be properly created and tuned in order to achieve the desired results. It is important to be aware of the restrictions, limits, and proper patterns, and situations when these features are appropriate etc. Even what happens “under the covers” should be clear.
In general, there are three important points to remember about autonomous transactions:
- They are powerful tools that allows us to solve old problems in new ways.
- They are complex tools requiring a high level of familiarity with the Oracle DBMS.
- They are sensitive tools that may result in unexpected (or even catastrophic) results if used improperly.
In summary, autonomous transactions are a very interesting feature can be very useful but must be handled carefully.
About the Author
Michael Rosenblum is a DBA at Dulcian, Inc. He also supports the Dulcian developers by writing complex PL/SQL and researching new features.