Object Types vs. PL/SQL Tables: 2 Practical Examples
Since the Oracle8 database was released, there have been many papers and presentations discussing the new features in SQL and PL/SQL. Most of these entail laundry lists of features with an overview of the syntax and its use, but few discuss how these features were used to solve specific real-world problems. There are often many different ways of solving a particular problem. As more and more new functionality is added to the tools, it becomes increasingly difficult to choose the appropriate one(s).
This paper will describe an actual problem encountered on a project for which a number of traditional techniques failed. The eventual solution in both cases used an object collection cast to a table as well as some other advanced features (e.g. Dynamic SQL and PL/SQL, REF Cursors, RANK). Looking through a book and figuring out how to use a new SQL or PL/SQL feature is not necessarily difficult. The tough part is determining when these new features might be useful and applying them accordingly.
NOTE: The same problems discussed in this paper are discussed in
the context of a reporting methodology in another ODTUG 2004 conference paper
entitled “Advanced Web-Based Reporting Techniques in PL/SQL” -
System Requirements
In building two different reporting systems, the following requirements were encountered. This section describes each requirement and the development environment available for the systems to be built.
1. Search engine requirement
In the first system example, there is a specialized repository (conceptually close to the Oracle data dictionary) at the top of the regular database. This repository is maintained by system architects and regularly has about 50 tables with 1000 columns in total. End users should be able to search through the tables registered in the repository; but at a certain point, not all elements can be available.
Additionally, the system architects needed to maintain a list of available options (tables and columns) as a subset of the total repository. This means that users can only access selected elements (usually 50 columns from 20 tables). The data dictionary is also partitioned by projects so that searches can be done by project or through all of the available data.
2. Reporting engine requirement
An apparently simple-looking report was needed based on a small number of warehouse tables. Although the real system was more complex, for the purposes of this paper, assume a single Customer table with 100 columns and some simple lookup tables. The simplified data model is shown in Figure 1.
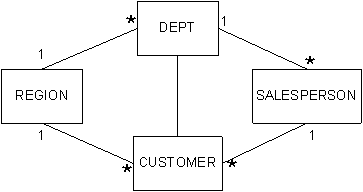
Figure 1: Simplified Data Model
As Customers are entered into the system, they move through different milestones. For example, Prospects may evolve into Leads which eventually turn into Actual Customers. (The real system included 10 different milestones.) For each customer, it was possible to track when each milestone was reached (attributes of the Customer table). Other Customer attributes included data such as date of birth, height, weight, etc.
Using a flexible reporting front-end, users could specify any
number of different filters such as “Customers over 40 years of age from
For the report, there were various levels of display options such as:
Region
Department
Salesperson
The detail of this report is at the Salesperson level, aggregating Salesperson details with breaks at the Department and Region levels. (The actual report hierarchy was six levels deep.)
Users were able to specify the desired level of detail in the report as well as where the breaks occurred. Columns of the report also needed to be user-specified. The columns were used to group customers who had reached a particular milestone or any one of a collection of milestones. Up to ten different columns needed to be specified for the report. Within each cell, users could select from any number (up to 20) of statistics such as average number of phone calls, average age, count of customers in each cell, etc.
This total reporting environment provided generic filtering, on-the-fly structural, column and statistic specification. A typical report specified by a user required 2-3 filter criteria, 3-5 levels of breaks (resulting in 200-400 rows in the report), 5 or more columns, and 4 or more statistics in each cell. The number of customers in the system Customer table was in the 5-10 million range.
Development Environment
The Java environment is not very friendly for communication with
the database. In the client/server environment, advanced transaction control is
a given. In this case, Oracle 9i JDeveloper
was used to build a JClient application using a BC4J (now called
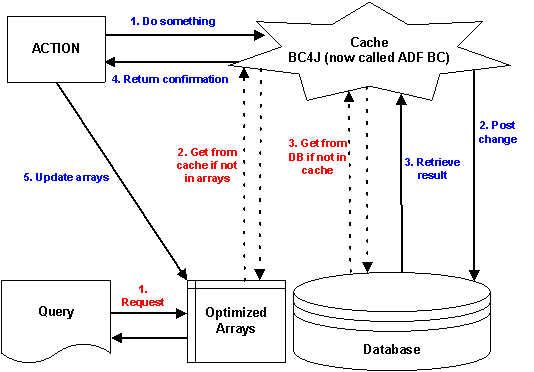
Figure 2: Action Flow in JDeveloper Client/Server Environment
The core issues to be considered are as follows:
· Synchronization between the database, the cache, and the arrays is a critical factor that should be considered before designing the communication logic.
· The design of the user interface was significantly different from the way in which the data is stored in the database.
· Actions on the result set involve much more than simple DML actions.
From the specifications, the application includes exception handling that is independent from the usual Oracle exception handling. For example, some exceptions should be raised on the database side, but should not have any impact on the client. Special routines had to be created to work with the cache.
The behavior of the database engine is very different from the middle-tier. At some point the logic needs to be “transformed” beyond what the tools are able to accomplish. The following section discusses one possible solution to the problem of meeting the reporting requirements for the two systems described above.
Solution
The logical construction of both reporting systems is very similar to the current web-environment in that the core idea of full separation between action and response on the Web correctly corresponds to the request/result pair of any reporting tool. For this reason, both cases can be examined at the same time and both include exactly the same major obstacles:
· Flexible data structure:
o “Floating” list of tables and columns (search engine)
o Breaks and statistics required “on-the-fly” (reporting engine)
· Front-end representation is very different from the database.
o Search results are generic and have no direct analogy with any element of the database.
o The report has too many dynamic elements to be generated into a database structure.
In order to solve both problems, another layer of abstraction is needed to handle generic requests and return generic answers.
Modifications to the multi-tier logic
The proposed solution is based on two Oracle features: object collections and dynamic SQL. In this context, the most important points about these two features are as follows:
1. Object collections are used to communicate between the front-end and the servers.
· An object collection is a memory structure. Performance-wise, it is much faster than temporary tables.
· A regular database view can be built at the top of the collection. This is not possible with PL/SQL tables. The reporting environment will see the data in the regular way.
2. Dynamic SQL allows the hard link between the code and data model to be broken.
· It is possible to open the cursor for the string created on the fly to allow for changes of both data sources and queried columns.
The new multi-tier logic algorithm used for processing is illustrated in Figure 3.
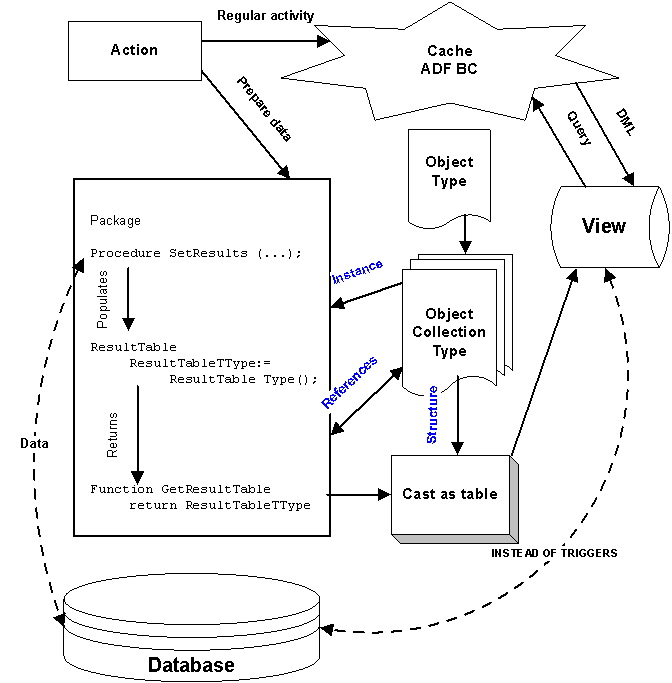
Figure 3: Modified Multi-Tier Logic
Preparation
Conceptually both problems are the same. However, the reporting one has other interesting aspects such as statistics. These statistics will be the basis for the code examples shown in this paper.
Developers have to decide what
ID Number,
ID_RFK Number,
Region_OID number,
Dept_OID number,
CustmrCount_NR number,
Break1_TX Varchar2(200),
…
Break10_TX
Varchar2(200),
Col1_TX Varchar2(200),
…
Col10_TX
Varchar2(200),
Level_NR Number,
Order_NR Number,
Populated_YN
varchar2(1)
Code Sample 1
Items in this code are identified as follows:
· ID = System-generated ID
· RFK = Recursive foreign key link to track what rows roll up to what other rows
· Breaks 1-10 = Descriptive row text
· Columns 1-10 = CHR(10) delimited list of statistics values for the report
· Level = Row level in a recursive hierarchy
· Order = Number of the row in the report
· Populated_YN = Used in processing the first detail and then aggregated upward to build the report
A new object type “ReportTableOType” should be built in the same was as the specified structure of the report (from Code Sample 1). Another new type “ReportTableTType” consists of the collection of the objects that belong to ReportTableOType (Code sample 2).
CREATE OR REPLACE type ReportTableOtype as object(
ID Number,
ID_RFK number,
...);
CREATE OR REPLACE type ReportTableTType as table of ReportTableOType;
Code Sample 2
In the package that builds the report, the “report table” (physically instantiated as a packaged variable of the type ReportTableTType) will actually be created. To be able to use that packaged variable in the SQL, a function is required to return the collection as shown in Code Sample 3.
ReportTable ReportTableTType:=ReportTableTType();
FUNCTION GetReportTable RETURN ReportTableTType IS
BEGIN
RETURN ReportTable;
END GetReportTable;
Code Sample 3
At this point, it is possible to build view at the top of the function call as shown in Code Sample 4.
CREATE OR REPLACE VIEW v_reporttable (
id,
id_rfk,
… )
AS
select r.*
from table(
cast
(OrgUnitReprt.GetReportTable as ReportTableTType)
) r
Code Sample 4
Data Access
Since the proper communication structure is known, the next step is to populate the created object collection with the appropriate data.
The core part of data querying is the dynamic cursor shown in Code Example 5. What is required is a new variable of type “ref cursor”. This is a large string used to store the SQL being built and the generalized record used to handle breaks, statistics, etc.
Type rep_cursor is ref cursor;
V_cursor rep_cursor;
V_sql_tx varchar2(32000) := ‘select ’;
Type return_rec is record (
breakValue1_CD
varchar2(200),
breakValue2_CD varchar2(200),
breakValue3_CD varchar2(200),
breakValue4_CD varchar2(200),
breakValue5_CD varchar2(200),
custmr_oid NUMBER,
custmr_rfk NUMBER,
salesperson_oid NUMBER,
desk_oid NUMBER
...
);
V_return_rec return_rec;
Code Sample 5
The required SQL string will be created based upon the user’s
request. It should exactly match the expected generalized record with some
placeholders. This provides enough
OPEN v_cursor FOR v_sql_tx
FETCH v_cursor INTO v_return_rec;
...
EXIT WHEN v_cursor%notfound
END
Code Sample 5
Statistics
At this point in the process, there is enough
The reporting engine requirement has another problem to contend with, namely, multiple statistics. Solving this problem also involves the crux of the solution for speeding up the report performance. A single query was used to walk through all of the Customer records. For this reason, rather than executing a query for each statistic, it is possible to update all of the appropriate statistics based on the values associated with the currently processed customer. The statistics were placed into an individual PL/SQL table using a simple hash function to concatenate the row, column and statistic number. This enabled easy insert and retrieval of statistic values. The code to create the PL/SQL table and the hash function to access it are shown in Code Sample 6.
TYPE StatsRec IS RECORD (Type_TX VARCHAR2(200), Stat_TX
VARCHAR2(2000));
TYPE ColStats_TType IS TABLE OF StatsRec INDEX BY BINARY_INTEGER;
ColStatsTab ColStats_ttype;
FUNCTION F_RowHash_NR(IN_Row_NR
NUMBER
, IN_Col_NR NUMBER
,
IN_Stat_NR NUMBER)
RETURN NUMBER IS
col_tx VARCHAR2(200);
stat_tx VARCHAR2(200);
BEGIN
col_tx :=
lpad(in_col_nr,3,'0');
stat_tx := lpad(in_stat_nr,3,'0');
RETURN
in_row_nr||col_tx||stat_tx;
END F_RowHash_NR;
Code Sample 6
A separate routine was used for each statistic type. This helped modularize the code and keep it well organized. The routine for counting customers in a particular cell is shown in Code Sample 7.
procedure p_StatCount(
in_ReptRow number,
in_col_nr number,
in_stat_nr number) is
v_hash_nr number :=
f_rowhash_nr(in_ReptRow,in_col_nr,in_stat_nr);
begin
ColStatsTab(v_hash_nr).Type_TX := 'Count';
ColStatsTab(v_hash_nr).Stat_TX :=
NVL(ColStatsTab(v_hash_nr).Stat_TX,0)+1;
end;---p_StatCount
Code Sample 7
Once all of the statistics are calculated, it is easy to loop through them to populate the CALL_TX columns in the main report table. The routine for doing this is shown in Code Sample 8.
procedure p_CopyColStatsTab_ReprtTable is
v_totalColumns_nr number
:= ReptColTab.count;
begin
--dbms_output.put_line('start copy');
for ReptRow in
ReportTable.first..ReportTable.last loop
if
ColStatsTab.exists(f_rowhash_nr(ReptRow,0,0)) then
ReportTable(ReptRow).CUSTMRCOUNT_NR :=
ColStatsTab(f_rowhash_nr(ReptRow,0,0)).Stat_tx ;
-- ReportTable(ReptRow).CUSTMRCOUNT_NR :=
ColStatsTab(f_rowhash_nr(ReptRow,0,100)).Stat_tx ;
end if;
for CountStat in
1..ReprtStatsTab.count loop
---------------
if
v_totalColumns_nr >= 1 then
if
ColStatsTab.exists(f_rowhash_nr(ReptRow,1,CountStat)) then
--ReportTable(ReptRow).Populated_YN
:= 'Y';
ReportTable(ReptRow).Col1_tx :=
ReportTable(ReptRow).Col1_tx ||
ColStatsTab(f_rowhash_nr(ReptRow,1,CountStat)).Stat_tx||
chr(10) ;
else
ReportTable(ReptRow).Col1_tx :=
ReportTable(ReptRow).Col1_tx ||chr(10);
end if;
end if;
---------------
…
end if;
end loop; ---stat
---remove trailing
chr(10)s from each cell
ReportTable(ReptRow).Col1_tx :=
rtrim(ReportTable(ReptRow).Col1_tx,chr(10));
ReportTable(ReptRow).Col2_tx :=
rtrim(ReportTable(ReptRow).Col2_tx,chr(10));
…
end loop; ----rpt row
end p_CopyColStatsTab_ReprtTable;
Code Sample 8
The final step involved copying the
PROCEDURE P_Rollups IS
CURSOR C_RowsToProcess
(in_level_nr number) IS
SELECT id,order_nr
FROM v_reporttable
WHERE populated_yn =
'N'
AND level_nr =
in_level_nr;
CURSOR C_ChildRows(cin_id
NUMBER) IS
SELECT order_nr
FROM v_reporttable
RptRow
WHERE
RptRow.populated_yn = 'Y'
AND RptRow.id_rfk =
cin_id;
v_complete_YN VARCHAR2(10);
v_hashParent_nr NUMBER ;
v_hashChild_nr NUMBER ;
v_hashParent_age_nr NUMBER ;
v_hashChild_age_nr NUMBER ;
v_hashParent_count_nr
NUMBER ;
v_hashChild_count_nr NUMBER ;
v_hashParent_time_nr NUMBER ;
v_hashChild_time_nr NUMBER ;
v_level_nr number;
BEGIN----- main rollups
select max(level_nr) into
v_level_nr from v_reporttable;
for countLevel in reverse
1..v_level_nr LOOP
FOR ParentTabRow IN
c_rowsToProcess (countLevel) LOOP
ReportTable(ParentTabRow.order_nr).Populated_YN :=
'Y';
FOR ChildTabRow IN
c_ChildRows(ParentTabRow.id)
v_hashParent_nr
:= f_rowhash_nr(ParentTabRow.order_nr,0,0);
--count
v_hashChild_nr := f_rowhash_nr(ChildTabRow.order_nr,0,0); --count
IF ColStatsTab.EXISTS(v_hashChild_nr) THEN
ColStatsTab(v_hashParent_nr).Type_TX :=
'Count';
ColStatsTab(v_hashParent_nr).Stat_TX
:=
NVL(ColStatsTab(v_hashParent_nr).Stat_TX,0)+
NVL(ColStatsTab(v_hashChild_nr).Stat_TX,0);
END IF;
---begin
calculation of statistics
FOR col_nr IN
1..ReptColTab.count LOOP
FOR Stat_nr IN
1..ReprtStatsTab.count LOOP
v_hashParent_nr :=
f_rowhash_nr(ParentTabRow.order_nr,col_nr,stat_nr);
v_hashChild_nr :=
f_rowhash_nr(ChildTabRow.order_nr,col_nr,stat_nr);
---main stats
type if
IF ReprtStatsTab(Stat_nr).reprtstats_cd IN
('Count', 'Phone', 'Email','Visit','AnyOutrch')
THEN
IF
ColStatsTab.EXISTS(v_hashChild_nr) THEN
ColStatsTab(v_hashParent_nr).Type_TX :=
ReprtStatsTab(Stat_nr).reprtstats_cd;
ColStatsTab(v_hashParent_nr).Stat_TX :=
NVL(ColStatsTab(v_hashParent_nr).Stat_TX,0)+
NVL(ColStatsTab(v_hashChild_nr).Stat_TX,0);
END IF;
ELSIF …
---many other stats
END IF;
---main stats type if
END
END
---end
calculation of statistics
END
END
END
P_PrintStats;
P_CopyColStatsTab_ReprtTable;
END P_Rollups;
Code Sample 9
The actual calculation of the statistics is relatively straightforward. The only place where this algorithm did not work was with some statistics that could not be handled, such as truncated averages. The requirement was to display the average age for the center two quartiles of the population within a cell. There was no way to run through the customers once and update the statistics. In this case, the RANK function was used to calculate the statistic in each cell where it was required.
Conclusions
In both of the examples discussed in this paper, performance is acceptable. The search engine has sub-second response times for most request types and the report runs very quickly. The initial setup and population of the report table with row data requires .2-.3 seconds. Copying the statistics to the report and the calculation of aggregate rollups requires .1-.2 seconds. Therefore, processing customers requires most of the time. Depending upon the power of the machine being used, approximately 10,000 customers/second can be processed. As long as the number of customers being processed in any report is in the tens of thousands, the report performance will be acceptable.
The same methodology discussed in this paper can be successfully used in two very different situations for both web-development and reporting tools. The solutions to the problems encountered often simply require a different style of thinking. In this case, object collections allowed us to create a more “clever” layer between the database and the client. The disadvantage of making the system more complex than before is outweighed by its increased flexibility ease of management for both users and developers.
About the Author