Using SOA with XML at the Application Level
Introduction
Service-Oriented Architectures (SOAs) are typically thought of as a means of transferring data between larger systems and subsystems in order to meet business requirements. However, this same strategy of defining a series of services to support a system’s business needs can also be adapted to provide the benefits that SOA offers at the application level. In a typical database-driven application, the interaction between the user interface (UI) and the database is made possible by the middle tier, which performs DML operations and queries data that is then packaged using a specific architecture and language. Unfortunately, this locks the UI, middle tier, and database together, so that changes to any one portion of the sysetm affect the others.
If a SOA-like strategy is used to support the interaction between the UI and database, you can decouple the UI, middle tier and databse, thus allowing UI and database developers to isolate their respective code. This architecture allows for independent implementation of the system front-end and back-ends. Adopting this design strategy also allows a larger portion of the application logic and business rules to be placed in the database where they can be modified in real time with little or no system downtime. Due to its growing popularity, standardization, and the complexity of data that can be represented within it, XML is an efficient transport medium for the data that can be passed between the front and back-ends of a system using a SOA approach.
Architecture
The de-facto standard for web-based and remote access systems is a three tiered architecture including a database, an application server, and the client user interface:
1. Typically the database acts almost exclusively as a data store, and may contain a small amount of business logic and system coding.
2. The application server handles much of the processing of user requests and compiling of the user interfaces in a web application. The middle tier is what truly binds everything together into one indivisible, often inflexible system. Depending upon the decisions made about how the middle tier will be coded and what off-the-shelf or custom architecture will be utilized truly drive the rest of the system.
3. The client normally renders the user interface and typically provides the user interaction in a web browser or a custom client application.
If your system development follows the direction of the new Oracle Application Development Framework (ADF) Faces architecture, the resulting system will be locked into that design methodology and it will be costly and time-consuming to migrate to a different architecture. Every few years, Oracle releases a new incarnation of BC4J/ADF that is different enough from the last version to require rewriting most (if not all) of the existing application to fit into the new framework. This often entails not only upgrading some core piece of the system, but also upgrading/rewriting each of the screens and processes involved because there are no well defined boundaries or interfaces in these architectures between the middle tier/database and the middle tier/client. Without these boundaries, changing any one element requires refactoring all of the rest. One way to avoid this problem is to create very specific boundaries within the system using well-defined services or APIs to link the different parts together. Using this approach, any one of the tiers can be swapped out with little or no modification of the others.
As an example of how this strategy can work, consider the implementation of a tree component built using this SOA approach as shown in Figure 1. A tree component is an excellent use case to examine since tree components can be powerful navigational aides with a lot of functionality incorporated into them. However, despite their complexity, most of the functionality of the tree component can be broken down into simple discrete actions such as expanding a node, selecting a node, and right-clicking a node. It is then possible to develop a service to support each of these functionalities to allow the tree component to communicate with the system back-end and perform the appropriate actions. Defining the tree component as an interface instead of as an instance of an implementation in another framework provides the flexibility to determine the look-and-feel of the front-end as well as select the appropriate architecture for the front-end, middle tier, and back-end. The goal is to be able to plug in substitutes for each of these tiers without having to refactor the entire system. Only some of the core components of the architecture would need to be modified to work with the substituted section.

Figure 1: JClient Implementation of Tree Component
System Structure
Because the middle tier holds the system together, the SOA approach to system design defines hard interfaces between the client, middle tier and database so that the design choices made in any one of these areas does not lead the system down a specific path from which it is difficult to deviate. In a typical system design process, the interface between the middle tier and database is nothing more than a database connection which prescribes use of the particular database syntax to access it. In addition, developers must have detailed knowledge of the database structure. Requests are processed by having the middle tier accept a request, make decisions about what should happen next, and then make frequent requests to the database for more information. This approach assumes that the middle tier developer has specific knowledge about the database syntax and the data model. While this approach is valid, it limits the modularity of your system. If the data model for a particular process changes, the middle tier will have to be refactored and retested to support the new structure. Using the tree component example, building the tree with a typical design methodology requires the middle tier developer to understand which tables hold the information for each of the nodes and how those records are linked together in order to form the hierarchy. Queries against those tables then need to be written to support the tree.
The alternative and more SOA-like approach to handling the middle tier/database interface is to define specific APIs to handle different types of requests. This way, the only pieces of information that the middle tier developer needs to know are what function to call in the database and the input parameters. If, at a later time, that API needs to be expanded or modified the changes to the middle tier would be relatively minor. Similarly, changes to the data model should not affect the middle tier at all since the only accessors from the middle tier are well-defined APIs.
This lack of interdependency most likely involves moving the business logic, process flow, and screen definitions into the database. Otherwise, the number and complexity of APIs will be too great to be useful. This type of middle tier defines the services that are available to the UI and handles requests to the database for processing and sending the results back to the client for rendering and input. Although the system would still include three tiers, the middle tier acts more as a conduit between the client and the database.
Using the tree component example again, the client makes a request to the middle tier service to initially build the tree. The middle tier performs the authentication allowing the user to make this type of request, exposes the service to the end user, and forwards the request to the appropriate database API. In this example, the API is defined as a single database function for all tree actions with the following input parameters:
1.) Unique session identifier - Used to track a user session and the current state of their tree
2.) User identifier
3.) Type of tree - Used to support multiple types of trees for a single user
4.) Action requested - In this case the action is to build a new tree
The database then processes the request internally, determines the hierarchical structure of the tree for this user, and generates a response that is passed back to the middle tier. The middle tier uses this response (which includes the specification of the action) to build a new tree and simply forwards it back to the client which performs the appropriate action identified by the database (in this instance render the tree to the user). This process continues back and forth with different types of requests for the different services exposed. For instance, a separate action might be executed to indicate that a node was expanded, and the return action might be to add several nodes underneath that expanded node.
The benefit of this architecture is that it includes a very well-defined set of interfaces between each of the tiers. If an organization needs to change from an Oracle Application Server to an IIS server, all that is necessary is to code the new middle tier to handle the same type of requests and forward them to the database. There is no need to refactor each page/screen from a JavaServer Page to an Active Server Page. If the database changes, the APIs must be implemented in the new database to process the same input parameters and generate the same output format. If the actions and business rules are well-defined in a repository, even switching to a new database would not be that difficult because only the engine that reads from the repository would have to be rewritten. If the client used to render and process the UI actions needs to be changed, the engine used by the UI will need to be refactored, but not every screen and widget will need to be rewritten. In our tree example, only the core code used to render the tree, process each type of fundamental tree action, and perform the appropriate response need to re-implemented. However, if multiple instances of the tree widget are used throughout the application or across many applications, then these modifications only need to be made once for the core engine to make them usable by all implementations of the component.
Transport Layer
The transport layer for this SOA approach to system design can include anything that satisfies the requirements of what needs to be implemented. XML is an obvious choice because it is easy to work with as a developer since it is readable by humans. There exists a wealth of good, mature utilities available to generate and parse XML structures in nearly every programming language and it is the transport structure already used in many SOAs.
The primary downside to XML is that due to its human readable structure there is some overhead associated with encoding data in XML. Overly descriptive naming tends to bloat the total size of the data being transferred when it is encoded in XML, resulting in more network traffic and longer wait times. Various techniques can be used to overcome this drawback such as shortening tag and attribute names and/or compressing the XML document before transport. Of course, XML is not the only choice. In fact whichever format is most beneficial for the task should be used; however XML should be usable for the vast majority of situations.
In our tree component example, the structure of the response to a request from the tree component might look something like the XML shown in Figure 2. The formatting and structure of the response would be a specification developed to support the specified business case. In this situation, the resultant XML would be a hierarchical structure representing the parent/child relationship of the nodes in this particular tree. Since XML and tree structures are hierarchical by nature, the two work well together since each XML node corresponds directly to a tree node along with its parent/child relations. The attributes of each of the nodes of the XML document indicate properties of each of the tree nodes. For instance, the root node of the tree in this example has a display attribute of “AFMS” which is used to indicate what the name of the node should be as shown in Figure 1. The ID attribute of that node indicates a unique identifier for that node in the tree, which can be used later on to identify a node upon which an action has been performed. There are also other attributes that will define the behavior of the tree nodes. For example, when a node is expanded, the Expand attribute determines whether an action should always be fired to request what nodes to show underneath it, or whether to only make that request the first time and cache the results. These types of specifications are completely implementation-specific, depending upon what you wish to support. You can include as little or as much detail in the XML result as needed.

Figure 2: Tree Response XML
This defined transport layer clearly demonstrates the versatility with this architecture. Since the specification for this tree widget is defined without regard for any particular platform, programming language, or implementation, what the client chooses to do with the data, is for all intents and purposes up to the client. Different implementations of the client can be coded against the same middle tier/database without any modification to the middle tier or database as long as they adhere to the same specifications.
User Interface Options
Using this application-level SOA approach to system design translates into an easily replaceable and customizable user interface. Because there is a platform-independent definition of the data being transferred back and forth, the user interface can be designed using whatever architecture the developer desires. If the system is already locked into a certain technology stack such as JSP/Struts, JClient, or Flash, this approach can be used, leaving the option open to switch to another stack if necessary. Figure 1 showed a JClient implementation of the tree component. Figure 3 shows the same functional tree implemented in a web-based JSP/JavaScript technology stack. The interesting thing about these two implementations is that they were developed separately by two different groups, neither of which had to make any changes to the database or middle tier.
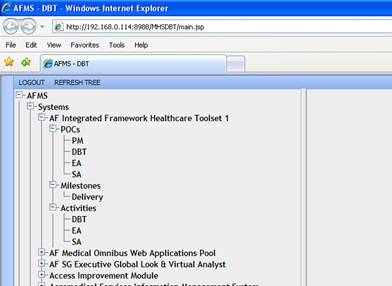
Figure 3: JSP/JavaScript Implementation of Tree Component
Case Study
Originally this architecture and tree component were explored for a customer with an existing JClient application that included a poorly designed tree component. When minor changes to some functionality of the tree were needed, these could only be accomplished by also changing the client Java code which then had to be deployed to several hundred users. In order to successfully replace the client-side tree, it was necessary to detect the following activities and inform the database:
1.) Request a new tree
2.) Expand or collapse a node
3.) Select a node (left-click node)
4.) Right-click node
5.) Drag and drop a node
6.) Select a menu item option
Based on the event, type of node, and the business logic associated with the particular object, one of the following actions can be presented to the client:
1.) Build a new tree
2.) Replace all nodes below a node (expand node)
3.) Insert a node
4.) Delete a node
5.) Update the properties of a node
6.) Execute a custom action
By implementing this small set of event listeners and actions as well as using a single API as the interface, it was possible to implement all of the functionality of the original tree along with all of the new requirements without ever having to redeploy the client code after the initial deployment. Once this new architecture was in place, the only portions of the system residing on the clients’ CPU were the tree renderer, event listeners, and action performers. All of the logic and rules had been moved out of the client code and into the database. Afterwards, when a request was made to change some of the tree functionality, the changes could almost always be accomplished using a minor database patch and no end user involvement.
The updated tree component was so successful that this same concept was used to develop a screen component to dynamically build screens with labels and fields that were defined in the database and delivered to the client as an XML document. Figure 4 shows an example of one of these dynamic screens.
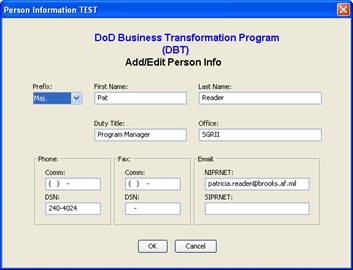
Figure 4: JClient Implementation of Tree Component
Later, the architecture was used for another client to define the same type of tree as a navigational aide, again using the JClient version of the user interface. To implement this change for the new client, no code in the user interface or middle tier had to be changed. The database was the only part that needed to be modified in order to handle their tree structure and required functionality.
After the tree had been specified in both the repository and PL/SQL code and the application was functional in JClient, a web-based implementation of the application was requested. Typically, going from a thick client to a web application entails a full rewrite of the entire system. However, in this case, it was only necessary to rewrite the UI renderer for both the tree and screen components to work in a JSP/JavaScript technology stack. None of the screen definitions, tree definitions, or business logic had to be modified to support this new requirement. In fact, development continued on the business rules and user interface screens using the JClient application as the testing bed, while another development team created a JSP/JavaScript version of the application in a matter of weeks. After the web version was delivered, there was no integration or migration necessary. Once the web application was pointed to the development database, all of the new screens were available and fully functional. Figure 5 shows an example of the web-based version of the screen shown in Figure 4.

Figure 5: JSP/JavaScript Implementation of Screen Component
Conclusions
The application development approach outlined in this paper is still a work in progress. It has not yet come to full fruition, but it has changed the way in which we think about application design, development, and how the process can be improved. After using this architecture on several projects for multiple clients, the following advantages were observed:
1.) Reduced interdependence between user interface, middle tier, and database
2.) Technology stack-independent specification
3.) Smaller network footprint
4.) Faster load times
5.) Centralization of business logic
6.) Faster development times
About the Author