Literate
Specification: A Tool for Documenting and Implementing Business Rules in the
Database
Introduction
A year ago a framework for documenting and implementing Business Rules (BR) in the database was presented. In that framework, the documentation was based on definitions of tables’ life cycles through state machines. The implementation was based on twelve triggers, a control package and BR packages. The transformations and top level BR were considered in the table’s life cycle definitions and were featured through a decision structure reflected directly in its implementation code.
Following that point, the need of implementation of other types of BR arose. In that moment, the BR were few, due to the fact that the framework started to be used. However, the BR began to grow until there was a moment where it got too difficult to keep track of the implemented BR in production.
The developers were able to understand the behavior of the records, determine the transformations and get to know the top level BR implemented on the transformations. On the other hand, they couldn’t understand the actions executed in the BR.
Now, what is going on in our case
After some time of implanting the framework, the methodology for developing the applications in the server side had changed, due to the framework’s demands. Now, the developers have to create the table schemes, deeming two extra columns in each table for storing the records’ current state and last transformation.
In order to implement a business rule, it has to be defined and registered inside the framework’s store tables, then linked to one of the table’s transformations.
After defining the necessary information (states, transformations and top level BR), the code of the triggers and the control package are generated and implanted in the database. The implementation code is generated through our own table’s application-programming interface generator from the framework’s storage tables.
Certainly, This was hard
Perhaps, the most important requirements for implementing this framework were: First, to include in each table two extra columns for storing the records’ current state and last transformation; secondly, the SQL sentences (insert, update or delete) couldn’t be used freely anymore. Now everybody had to know the transformation that was needed to apply over the record(s) and specify it in the sentence -except in the delete sentence; last of all, the BR had to be documented before their implementation.
What’s more, this is going on
On the other hand, after the implementation of the framework the transition diagrams are used more frequently in the meetings where the systems are defined. Usually, our trainers use the transition diagrams to explain the business document behavior to the final users, those are better understood from their life cycle definition sketched as transition diagrams.
Now, the developers don’t have to pay attention to the triggers and other details related to the tasks that the framework is in charge of doing. On the contrary, they are more concentrated in the implementation of the top, middle and low level BR. They are sure that the framework is working and that the BR is run and applied correctly after their installation.
Not all seems to be a piece of cake
Although all rules have to be documented before being implemented, apparently this could be a suitable manner to get the BR going. However, that is not true because the BR full documentation and implementation haven’t been achieved completely. On the other hand, the relations among top, middle and low level BR are coded and not documented.
For overcoming those limitations and for avoiding the BR specifications separated from their documentation; and for dealing with the BR in the same manner as they are written and declared within businesses’ documents, a textual specification language has been developed.
Taking into account that the framework is working and brought into production, this paper presents a simplified literate specification language as a tool for defining and storing BR inside this framework. Pertaining to this language, its features and its sentences will be discussed. The entity’s life cycle will be proposed as the core and the most important concept for achieving the documentation and implementation of BR in the database. Finally, an abstract machine will be presented for explaining how the specifications in this language are executed.
Literate Specification Language
In the business context, commonly, the rules are written and declared within businesses’ documents in textual form, also the people –business rule experts, analysts and developers- involved in the businesses’ information systems definition are used to seeing and dealing with them in the same manner.
The literate specification language proposed, is a simplified version of a literate language. Through the use of this language the business knowledge is organized in a textual manner, with subtle syntax impositions, unpretending but also robust.
The know-how and good criteria of the business rule experts, analysts and developers for arranging the business knowledge along with the capabilities of this language can make a powerful tool for obtaining specifications near to the BR statements. Furthermore, this language tries to extend the information that defines a table, that is, not only its definition as such but also its life cycle, transformations and rules.
Features
The main feature of this language is its ability for combining text with its syntactical pinpointing within a single unit of specification code. The business rule experts, analysts and developers can guide those characteristics to give sense to its specifications. As viewed from another perspective, they can define their own language within this one.
It has three sentences
The sentences of this language are guided to specify: the life cycle, related to a table, in which the states, transformations, transitions and default rules are declared; the transformations, declared in the life cycle among which the top level BR are programmed to be applied over a table’s records; and the rules, through which the actions and decision structure are established –Table 1 summarizes the language sentences.
It uses five tags for remarking
The grammar structure for the language’s sentences includes directive, guide, rule, pattern and end tags, those tags are used to remark decision criteria, decision paths, actions (also conditions), chunks of rules and the finish point of a pattern of tags, respectively.
The directive tag is used to point out the decision criteria and condition rules as directives in a sentence, a directive is valid from its declaration until another directive is set up. The guide tag is used to mark the decision paths, each decision path is labeled with its mark in order to determine the decision path to follow. Combining both directive and guide tags, it is possible to built many kinds of control structures to direct the flow in a sentence.
Table 1. Language’s sentences
|
Sentence
|
Purpose |
|
Rule |
This sentence lets organize the knowledge implied in a rule. Rules of action and condition. are specified with this sentence. |
|
Transformation |
This sentence lets program the top level rules to be applied over a table’s records. The transformations are organized as another rule. |
|
Lifecycle |
This sentence lets: establish the states in which the table’s records might be; declare the tables’ transformations; enunciate the transition constraints between states; and define the default rules. |
Table 2. Language’s tags
|
Tag
|
Purpose |
|
(directive) |
This tag lets designate the flow control directives. Many decision criteria are joined in only one directive through the & operator such as the following example (CRITERION_1 & ... & CRITERION_N). In addition, this tag allows to remark the rules of condition as (Condition_rule_descriptor). |
|
[guide] |
This tag lets include marks for guiding the control flow. Each directive is instanced as [GUIDE_1| ...| GUIDE_N], these marks direct the flow along the sentence. |
|
<rule> |
This tag lets declare the rules descriptors. Commonly, this tag includes an identifier of a rule. |
|
{pattern} |
This tag lets put text and other tags including itself together in valid combinations of rule chunks. |
|
\ |
This tag lets finalize a pattern of tags. It is used to prevent the ambiguity in the patterns of tags. |
The rule tag is taken into account to emphasize actions and determinations taken in a sentence, each action or determination is included as a descriptor through this tag, which identifies the rule along the specifications. The pattern tag is employed to organize other tags, including itself recursively within valid rule chunks. Joining both rule and pattern tags it is feasible to organize the actions inside of a sentence in many manners –Table 2 summarizes the language’s tags.
The rule descriptor is used to identify an action, it can be considered as primary documentation too, for this reason the descriptor must be as clear as possible to understand the rule intention.
The end tag (\) is used to elude the ambiguity within the specifications. It must be included for indicating explicitly the place where a pattern of tags finish.
Through the tags, this language is trying to hide a rule’s specific knowledge (actions, decisions and entities). The tags also let prevent early considerations of implementation. The directive and guide tags avoid the use of control sentences as commonly done in programming languages, as well as the implementation considerations of the conditions.
It intermingles text among the tags
The text is freely intermingled among the tags for giving sense to the sentences, also to explain the sentences’ intention much better. This language, by using the tags, is trying to encapsulate and hide the specific knowledge, nevertheless, with the text, it is trying to clarify the pinpoints made with the tags.
The specifications of the language
This language intends to achieve a type of programming free of syntax burdens, this can help specify rules in natural form. The specifications would include not only references to the actions, conditions and determinations of the rules, but also to the documentation, altogether in a single document.
The literate specification lets represent many kinds of constraints: the standard and database constraints can be implemented within the lifecycle sentences as default rules; the transition constraints can be implemented grouped inside the transformations as top level rules; the column constraints, not only those related with their legal values but also those that involve value combinations, can be implemented inside the transformation and rule sentences.
Although, it isn’t evident in the specifications, the grammar of this language is oriented towards the specification of BR’ knowledge as a set of actions and determinations applied through the decision structure without involving specific code as done in usual language programming.
Rule tag’s role
Implicitly a decision tree with the tags is being built, where the directive, rule and pattern tags establish the decision tree’s nodes whereas the decision tree’s paths are labeled by the guide tags. The terminal nodes match the low level BR and the intermediate nodes match the top and middle level BR. Each transformation sentence as well as the default rules declaration match a decision tree -Table 3 summarizes the rule tag interpretations.
Table 3. Rule tag interpretations
|
Type
of rule tag |
Interpretation
|
|
State |
<State_Name, String_Constant> |
|
Transformation |
<Transformation_Name, String_Constant, Type_of_Sentence> |
|
Transition |
<State_Name, Transformation_Name, State_Name> |
|
Action |
<Action_Rule_Descriptor> |
Inside of the Business Rules
A business rule contains three kinds of knowledge: actions (or logic), that refer to the knowledge of ‘How’ to do something; decisions (or control information), that relate to the knowledge of ‘When’ the actions will be applied; finally, entities (or objects), that identify to ‘Whom’ the actions and decisions will affect and will be applied to.
The logic of a BR relates to the actions of: calculus, validation, verification, propagation and synthesis. The control information describes the decision structure or the different ways to reach the logic application, finally the objects group the entities involved in the rule that can be affected by the set of actions and decisions.
What rules have been considered?
With the goal of establishing a hierarchy of execution and application of rules, these have been classified in the following: high, top, middle and low level rules. The high level rules are those rules that are put into effect at table level when an insert, update or delete sentence is executed. The top level rules are those rules that are part of the definition of a transformation and these are applied at record level. The low level rules are those rules that are applied deeply at the end of each top level rule; finally a middle level rule is neither top level nor low level rule.
The transformations, transitions and default rules are always high level BR, these are the first to be put into effect just after the insert, update or delete sentence occur. These rules are always going to be applied at table level when any event takes place. With this type of rules the standard and database constraints can be carried out. For example, when a standard establishes that the user’s permissions for changing table’s information must be verified and user’s audit information must be registered.
Entities’ Life Cycle
The core and most important concept for achieving BR implementation and documentation in the database is the entities’ life cycle. All the businesses’ entities, as any other physical or logical entity in the real world, have a life cycle.
The life cycle is a model that defines the entity’s behavior, since it is created until it is removed definitively. Normally this model is described by its states, symbols and transitions.
In this particular case, this model is a little different in our framework because the symbols are replaced by the transformation’s names. In consequence, the transitions are established from one state to another by means of a transformation.
Figure 1 shows an example of transition diagram for the Bank Account entity, this includes five states (OPENED, PREPARED, OPERATING, SUSPENDED and CLOSED) that symbolize the possible states in which a Bank Account might be, the START and END states are representative only. The transformations OPEN, MODIFY, WITHDRAW and the others can be applied in order to change the Bank Account entity.
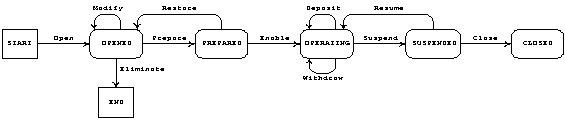
Figure 1. Bank Account entity transitions diagram
The life cycle lets establish a manner of processing the entities, that is, step by step, transformation by transformation from the very first time of their creation until their definite removal from the database. Many times, the changes that affect an entity must be spread over other entities, this can be achieved in a natural way through the insert, update and delete sentences.
Entities’ moments synthesized in States
In the life cycle the states define the moments in which an entity might be, in those moments the entity’s transformations can be put into effect. There are two states in which it can’t remain, these are: START and END states. The entity’s life cycle will have only one START and END states, but many states of transformation.
Entities’ changes accomplished by the Transformations
The transformations are rules that define the most important events that might occur over an entity. A transformation must be typified as a creation, modification or elimination event to keep its relation with the sentence from which it is being triggered.
The transformations are a manner to carry out the transition constraints, those constraints are specified as patterns of top level rules, classified by the moment (Before or After) and the level (Row or Statement), taking into consideration that these rules will be executed on an Oracle Database Engine.
Entities’ transformations constrained by the Transitions
The transitions are also rules, which prevent improperly usage of the transformation over records. Not all states of an entity accept to put a transformation into effect, those restrictions are determined by each transition.
In the delete sentence it’s not possible to specify a transformation, in this case the transformation is inferred from the transitions, this causes that only one transition by transformation of elimination exists from any state to the end state.
|
lifecycle
BANK_ACCOUNTS { (TYPE_OF_RULE) [STATES] { <OPENED, ‘The Account is empty and
recently created’> <PREPARED, ‘The Account is prepared
for entering in operation’> <OPERATING, ‘The Account is
operating’> <SUSPENDED, ‘The Account is out of
operation’> <CLOSED, ‘The Account is
closed’> } [TRANSFORMATIONS] { <OPEN, ‘Create a new account’,
INSERT> <MODIFY, ‘Modify a new account’,
UPDATE> <ELIMINATE, ‘Delete a new account
definitively’, DELETE> <PREPARE, ‘Prepare for entering a
new account in operation’, UPDATE> <RESTORE, ‘Restore the account
preparation’, UPDATE> <ENABLE, ‘Enable a prepared account
for operating’, UPDATE> <DEPOSIT, ‘Propagate the deposits
to an operating account’, UPDATE> <WITHDRAW, ‘Propagate the
withdrawals to an operating account’, UPDATE> <SUSPEND, ‘Suspend an operating
account’, UPDATE> <RESUME, ‘Resume a suspended
account’, UPDATE> <CLOSE, ‘Close a suspended
account’, UPDATE> } [TRANSITIONS] { <START, OPEN, OPENED> <OPENED, MODIFY, OPENED> <OPENED, PREPARE, PREPARED> <PREPARED, UNPREPARED, OPENED> <PREPARED, RESTORE, OPERATING> <OPERATING, DEPOSIT, OPERATING> <OPERATING, WITHDRAW, OPERATING> <OPERATING, SUSPEND, SUSPENDED> <SUSPEND, RESUME, OPERATING> <SUSPEND, CLOSE, CLOSED> <OPENED, ELIMINATE, END> } [DEFAULT RULES] { <control the permissions and
register audit information> } } |
Figure 2. Life Cycle specification
Life Cycle’s Literate Specification
The lifecycle sentence lets specify the entities’ life cycle, within this sentence the states, transformations and transitions are declared as patterns of rules. At the same time, this sentence is used to set up the pattern of default top level rules. There are many types of rules inside the previous patterns expressed by the rule tag.
The states, transformations and transitions are enunciated through the rule tag. This tag is interpreted as: <State_Name, String_Constant> when it is declaring a state; <Transformation_Name, String_Constant, Type_of_Sentence> when it is defining a transformation; <State_Name, Transformation_Name, State_Name> when it is establishing a transition -see also Table 3.
Figure 2 shows the Bank Account entity’s life cycle specification, in which the rules applied to the accounts have been specified and classified by (TYPE_OF_RULE) directive. It also declares [STATES], [TRANSFORMATIONS], [TRANSITIONS] and [DEAFULT RULE] patterns. Each pattern includes declarations of: states as <OPERATING, ‘The Account is operating’>; transformations as <DEPOSIT, ‘Propagate the Deposits to an operating account’, UPDATE>; transitions as <OPERATING, DEPOSIT, OPERATING>; and default rules as <control the permissions and register audit information>.
Specifying the transformations
The transformations declared within the lifecycle sentence have to be specified as a separated unit through the transformation sentence. The top level rules grouped in a transformation sentence are classified by the (MOMENT & LEVEL) directive –see Figure 3. The [BEFORE ROW], [AFTER ROW] and [AFTER STATEMENT] guides direct the flow control to their patterns of rules. Changing the decision directive, those patterns might be classified under other criteria or simply not classified. Each transformation can have many top level rules related to it, thereby, those are applied over each record affected by the insert, update or delete sentence.
Figure 3 shows the specifications of OPEN, MODIFY and WITHDRAW transformations chosen from Bank Account life cycle specification. Inside them two rule patterns are shown labeled with the [BEFORE ROW] and [AFTER STATEMENT] guides. The actions <check the user’s permission over transformation> and <deduct the quantity withdrawn from the account’s balance> are top level rules.
|
transformation
OPEN { (MOMENT & LEVEL) [BEFORE ROW] { <check the user’s permission for
executing the transformation> <validate the column’s values> <assign the columns’ default
values> } [AFTER STATEMENT] { <save audit information at record
level> } } transformation
MODIFY { (MOMENT & LEVEL) [BEFORE ROW] { <check the user’s permission for
executing the transformation> <check the transformation’s
permissions for changing the columns’ values> <validate the column’s values> } [AFTER STATEMENT] { <save audit information at record
level> } } transformation
WITHDRAW { (MOMENT & LEVEL) [BEFORE ROW] { <check the user’s permission over transformation> <check the transformation’s
permissions for changing the columns’ values> <validate the column’s values> <deduct the quantity withdrawn from
the account’s balance> } [AFTER STATMENT] { <save audit information at record
level> } } |
Figure 3 Transformation specification
|
Rule
<control the permissions and register audit information> { (MOMENT) [BEFORE] { <check the user’s permission over a
table> <check the user’s permission for changing
table’s records> } [AFTER] { <save audit information at table
level> } } rule
<validate the column’s values> { (TRANSFORMATION) [OPEN] { <verify the information of the
owner of the account> <verify the account’s characteristics> } [MODIFY] { <verify the information of the
owner of the account > <verify the account’s
characteristics>| } [WITHDRAW] { <verify that the quantity withdrawn
is greater than cero> } } |
Figure 4. Rule specifications
Specifying rules
The rules of action and condition that are concerned in the life cycle and transformation specifications have to be extended in a separated specification unit by a rule sentence. The low level rules mustn’t be specified in this manner, because they are translated directly into implementation code.
Figure 4 shows two specifications of rules: <control the permissions and register audit information> and <validate the column’s values>. At the beginning of both specifications the (MOMENT) and (TRANSFORMATION) directives are included for bolding out the classification criterion of the rules. The [BEFORE] and [AFTER] guides in the <control the permissions and register audit information> rule, as well as the [OPEN], [MODIFY] and [WITHDRAW] guides in the <validate the column’s values> rule, direct the control flow in the rule sentence.
The specifications of Figure 4 also include middle and low level rules such as <check the user’s permission for changing table’s records> or <save audit information at table level> in the <control the permissions and register audit information> top level rule; and <verify the information of the account’s owner> or <verify the account’s characteristics> in the <validate the column’s values> top level rule, these might be translated into implementation code or specified as other rules once more.
The intermingled text within the specifications
The lifecycle, transformation and rule sentences can freely intermingle text among the tags. This lets organize these sentences much better and improve their intention and meaning. In the same manner, emerges a document that is suitable for: understanding the behavior and transformation of the records in the tables; establishing accurately the moments when the rules are applied; and achieving appropriate communication of knowledge among business rule experts, analysts and developers.
The specifications of the WITHDRAW transformation and <validate the column’s values> rule showed in Figure 5 are examples of how the text might be used for clarifying the specifications.
It is possible to set up the language’s characteristics with text in order to change its fashion and to assemble a new language in itself. Figure 5 also exhibits the action rule <verify the account owner’s information> and the conditional rule (the account owner’s information has been changed), the last rule includes an emulation of the if/elsif/else PL/SQL sentence. Taking into consideration that if, elsif and else words is text intermingled among the tags. The <return TRUE> and <return FALSE> are action rules that will be translated into implementation code immediately.
The intention of the examples of specification in Figure 5 is
only illustrative of how the text might be intermingled with the tags for
building other sentence structures.
|
transformation
WITHDRAW { When withdrawing a certain amount of
money from an account, the following BEFORE
ROW and AFTER STATEMENTS actions or controls must take place according to the (MOMENT & LEVEL): when it is [BEFORE ROW] then, the engine
must: { <check the user’s permission over
transformation>, <check the transformation’s
permissions for changing the columns values>, <validate the column’s values>
and <deduct the quantity withdrawn from
the account’s balance> }; finally, when it is [AFTER STATEMENT]
then, the engine must { <save audit information at record
level> }. } rule
<validate the column’s values> { The column’s values of an account must be
validated according to the transformation, when the account is being
Opened, Modified or when a certain amount is withdrawn. In case the (TRANSFORMATION): Is [OPEN], then engine must: { <verify the information of the
owner of the account>, <verify the account’s
characteristics> }; Is [MODIFY], then the engine must: { <verify the information of the
owner of the account>; and <verify the account’s
characteristics> }; Finally, if it is [WITHDRAW], the engine
must { <verify that the quantity withdrawn
is greater than cero> }. } rule
<verify the information of the owner of the account> { In case (the information of the owner of
the account has been changed) Is
[TRUE] { <validate the telephone number> <change the first name to
uppercase> <change the last name to
uppercase> } it is [FALSE] <return> } rule
(the information of the owner of the account has been changed) { if (the first name is changed) then
<return TRUE> elsif (the last name is changed) then
<return TRUE> elsif (the telephone number is changed)
then <return TRUE> else <return FALSE>\ } |
Figure 5. Text within the specifications
Language’s Abstract Engine for running BR
The language’s abstract engine to enforce the specifications supports creation, modification and elimination events. Each one of them can transform businesses’ entities from their current state to another state individually or collectively. The abstract engine showed in figure 6 can be viewed from three perspectives, as an insert, update or delete engine. In each case it is set up in a different manner, with distinct devices and with another behavior as well.
It has many devices inside its structure
This engine -see Figure 6— has three tapes to store the entities that are involved in the insert, update or delete events. The new tape stores all entities that will be affected by the insert or update events; the old tape stores the last version for each entity affected by update or delete events; and the now tape stores all entities that are successfully transformed by the engine.
The entities in the now tape are those that: will be stored permanently when this engine processes the insert and update events; and will be removed definitively when the delete event is processed.
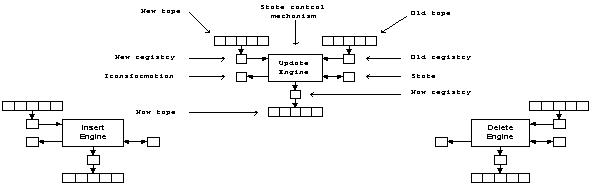
Figure 6. Language’s Abstract Engine
The engine also has three read/write heads for reading or writing the entities from or to the tapes. In relation with those heads there are three registries corresponding with new, old and now entities. These registries are utilized to retrieve the current entity from the new, old and now tapes. In each moment the reading/writing heads are synchronically moving over the tapes examining the same position as the others. This is made while the last entity on each tape hasn’t been processed successfully. The heads skip to the next entity once until last entity has been processed.
Also, the engine has two special registries to store: the current transformation that the engine is processing and the entity’s current state. With insert, update or delete events only one transformation can be applied, that means that all entities will be changed by the same transformation, but it doesn’t necessarily mean that each entity was or will be in the same state as other entities before or after their transformation.
It works as a control and application mechanism of BR
The engine has a state control mechanism, which is in charge of constraining the inappropriate application of the transformations. When an insert, update or delete event is processed, this mechanism is set up to control and direct the execution of the business rules.
First, the engine executes the default rules in the BEFORE moment, then determines the transformation to be applied to the entities based on the insert, update or delete event. It continues with the validation of the transformation in relation to the rules of state transitions.
After setting up the transformation, for each entity concerned in the event, the transformation’s top level rules in the BEFORE ROW, AFTER ROW and AFTER STATEMENT moment and level are executed. Each top level rule is in charge of executing the middle and low level rules.
Finally, after the last entity is successfully processed, the default rules in the AFTER moment are enforced, then the engine is shut down.
By means of this engine the implementation framework insures that all the business rules implanted are put into effect when any insert, update or delete sentence is sent to the database from an application. If somebody tries to change anything in the database tables, then this engine is triggered and its control infrastructure begins to run.
Documentation framework
The documentation is based on the rule, transformation and lifecycle sentences of specification. These specifications are compiled to obtain the necessary information for documenting the BR. Perhaps, the most important fact is that by means of the language’s compiler, enough information is produced for generating any kind of documentation.
Storing Information through the compilation
The language’s compiler lets procure lots of information from the specifications and store it in the framework’s table scheme –see Figure 7. In the table scheme, information (states, transitions, low level rules and other) obtained from lifecycle, transformation and rule sentences is stored.

Figure 7 Framework’s table scheme
The top, middle and low level rules are stored in the Business Rules table. The relations of the life cycle with its transformation and its rules are entered in the Default Rules and Top Level Rules tables. The remaining information (states, transformations and transitions) is stored in tables with their same names. The associations of a top level rule with its middle and low level rules are recorded as text in the Business Rules table.
Combining the language’s features in the specifications, it is possible to achieve documents suitable for automatically: storing information, that defines the tables’ life cycle, transformation and rules through the compilation process; and generating documentation.
Implementation framework
The implementation structure for running the specifications is based on the Oracle Database Engine. The abstract machine’s behavior and devices have been implemented as PL/SQL tables, triggers, packages, procedures and database tables. Much of that information must be active –p. e. Transitions table- in runtime for controlling the events.
When an insert, update or delete sentence is sent by an application (Form, SQL/Plus or other), the database triggers are in charge of putting into action the infrastructure for giving attention to the transformation specified with each sentence.
Abstract Engine’s tapes and registries implementation
The tapes of the abstract engine are implemented as a PL/SQL table and the registries as record type variables, both declared within the control package. The coupling of rules is carried out by the control package. Along the implementation code of rules and transformations, the PL/SQL table and the variables are known and available. All the control package variables are propagated from the database triggers to the implementation code of the low level rules. When the current transformation is enacted for being processed over each record, the New and Old records also are propagated to low level rules.
Abstract Engine’s behavior implementation
The behavior of the abstract machine is implemented by the procedures included in the control package and the triggers installed in the database. Both of them are in charge of verifying the transition constraints and executing the rules’ implementation code. Twelve triggers made up of the combination of moments (Before and After), levels (Row and Statement) and sentences (insert, update and delete) are put into action. Over those triggers the procedures that: control the transition constraints, execute the default rules and apply the transformation are installed.
Each transformation’s procedure calls to the top level rules procedures in the appropriate moment and level (Before Row, After Row or After Statement). All of the top level rules’ procedures are declared with new and old parameters of record type for being called in a standard way. Currently, the low level rules are still implemented manually by the developers as specific PL/SQL code.
Code Generator, our best programmer
Our code generator lets obtain the implementation code for the twelve triggers, the control package and rule package. The control package includes: the PL/SQL table; a procedure for validating the transitions; and a procedure for each transformation. By the moment, it isn’t possible to generate code for the low level rules, solely code for the top and middle rules can be generated within the rule package.
This code generator is macro-based, that is, a macro code for each generated unit (trigger, procedure, specification package, body package and others) is established and stored in a table of macros. The generator gets the corresponding macro and intermingles it with particular table information in reference to its life cycle, transformations and rules so that the code can be produced. The macros give flexibility to the code generator, due to the fact that those can be changed freely for optimizing and improving the code generated.
Experiences and Conclusions
In our case the development methodology has been changed
In our case from the moment this framework was brought into action, the development of applications in the server side hasn’t been the same anymore, due to the fact that the developers have gotten into a rule-based programming paradigm, where the applications have to be thought in terms of BR.
The developers have gotten used to working in this manner, now their jobs are limited to translate low level BR in specific PL/SQL code. Nonetheless, now they -together with the analysts- have to focus in the BR definitions.
After installing the framework over a table, everybody is aware that the framework is responsible for controlling and applying the BR in the database.
At some future date, with the help of the language, probably the Analysts and Business Rule Experts will be more involved in the development and maintenance of BR specifications, or will simply share the responsibilities over these specifications.
The language lets implement many types of BR
Before the language, our framework used to allow the implementation and documentation of the transformation, transition and top level BR. With this language, the framework capabilities of implementation and documentation were improved in relation to the default, middle and low level BR.
However, some problems gain importance
Still the low level BR have to be translated into PL/SQL implementation code manually, those BR are neither interpreted nor classified. They are used as documentation for giving sense to the specifications instead. It has only been achieved to encapsulate and hide the specific knowledge by the language’s tags.
In this sense, the next step to take is to upturn our code generator for obtaining specific PL/SQL code for low level BR. Other problems related to the dynamic on/off switching of the BR in runtime and those caused by the BR that affect recurrently a table, will also be the next objective to be cleared over through the framework.
Acknowledgments
I would start with a kiss to my son Ariel and my daughter Erika to whom I still owe much of my time, which I spend working. After that, I would like to thank my colleagues and friends at Project ILACO II from whom I received advice and support. Similarly, thanks are due to Gonzalo, Benjamin and Juan Carlos at the Centro Boliviano Americano, who have helped me to complete this paper. I want to thank Cristina Aramayo C.E.O. of Open Systems Trading & Consulting S.A. who is Oracle representative in Bolivia. I would finish with a plea for all people from Potosí in the city of La Paz who bear with the worst way of discrimination, poverty and hunger.