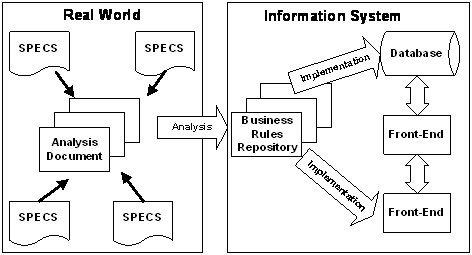
This structure provides a great deal from a technical point
of view. Since the repository is inside of the database, you can communicate
with it and therefore dynamically control the processing workflow. This raises
the issue of compiled code vs. interpreted code. In the current business rule tool
market, there are products that support both paradigms. At this point, a
comparison of the two approaches is useful.
1. Accessing the Business Rules Repository Using Interpreters
For years the most popular implementation idea of business
rule-based systems was the idea of real-time access to the set of business rules.
For example, the start date of an employee’s timesheet should not be later than
its end date. Using this example, the processing follows these steps:
1.
Detect the point when rule should be validated - “Submitting
the timesheet to the manager.”
2.
Find the appropriate rule in the repository - “Find all
rules that should be checked before the timesheet goes to the manager.”
3.
Translate the rule from business terms to database
terms - “Get Timesheet.StartDt < Timesheet.EndDt as the equivalent of Start
date should be less then end date.”
4.
Database validation using the interpreted rule and
original object - “Since the rule requires true/false answers, the database
validation function should return TRUE or
FALSE.”
5.
Interpret the result - “Result TRUE
means that the rule succeeded; FALSE means that it failed.”
6.
Flag the main routine regarding the success or failure
of the rule and execute appropriate actions. “IF rule succeeded, THEN send timesheet to manager; ELSE
show error message and return it to employee.”
It is pretty clear that the solution using interpreted rules
described above has many advantages. Changes to business rules and changes to
their interpretation have an immediate impact on the system. But there is a
major performance drawback because the database must perform many operations
just to compare two dates.
2. Generation from a Business Rules Repository
The opposite approach involves emphasis on faster performance.
Why not generate the rules directly into the system? Using the example above,
the logic could be as follows:
- The validation
firing point should be the state change of the timesheet from NotSubmitted
to Submitted. In the database, that rule could be implemented on the BEFORE
UPDATE trigger.
- If a
rule fails, an exception must be raised.
The code based on this logic might look like this:
CREATE OR REPLACE TRIGGER timesheet_bu
BEFORE UPDATE
ON timesheet
REFERENCING NEW AS NEW OLD AS OLD
Begin
if updating('state_cd')
then
if
:new.state_cd='Submitted' then
if :new.start_dt>=:new.end_dt
then
raise_application_error(-20999,'Rule 10 violated: start date cannot be
later than end date');
end if;
end if;
end if;
end;
Aside from the performance benefits to this approach, there
are some drawbacks. Any modification to the business rule now will require
regeneration of the objects that reference it. This can cause significant
problems in a production system because of the Oracle feature of invalidating
all objects referencing recompiled ones.
Common feature of both approaches
Because both approaches have advantages and disadvantages,
the choice of which one to use depends upon each system’s specific
requirements. However, both approaches have one major concept in common:
The implementation of the business rules is independent
of their specification.
Using the example “start date of the employee’s timesheet
should not be later than its end date,” there is absolutely no mention of
tables, columns, queries etc. It is just a rule. It is the system architect’s problem
to determine the appropriate implementation mechanism. Using the interpreted
approach involves translating the rules
into database terms and the results from the database terms by generating SQL,
XML, conversion maps etc. The second approach generates the database or other
objects using PL/SQL, Java, XML, JSPs, etc. in order to implement the business
rules.
Generators as a Core Part of Business Rules-Based Systems
From the discussion above, it is clear that no business rule
system could be implemented without some type of code generators. Only
generators can efficiently and cost-effectively support all of the system
requirements:
- Generators
can be tuned or changed without even touching the business rules. The expected
performance could be achieved without a major re-architecting of the
system.
- If
new requirements can be stored in the repository, the generators can be
updated to support them. Other parts of the system will not be affected by
the changes.
- The generation
algorithms can be changed depending upon the available data volume, system
configuration, etc.
- Generators
can be substituted or extended to work with other languages and platforms
without altering the business rules.
The following are some examples of different kinds of generators.
A. Interpreters
Many business rules need to be accessed in real-time. They
may be of very different types as discussed in the examples in this section.
I. Declarative business rule generators
There have been many attempts to create a pseudo-language
that would allow the definition of a rule written in more-or-less readable
English to be easily translated into a set of database commands and conditions.
Most of these attempts did not perform as promised. Some may solve specific
problems, but these implementations are very limited. In the real world, few IT
environments need to support thousands of declarative rules (Ex. “If gender is male and age is above 45, then
recommend yearly heart checkup”). Even in very large systems, there may only
be a few hundred of them spread around the large data or process model. In that
case, rather that creating an extra language there is a better, more flexible
solution.
The rule mentioned above is a good case for using a state-transition
engine as shown in Figure 2.

Figure 2. Basic State-transition flow
This shows a transition with the rule on it. If it succeeds, the object will be moved to
the state “Recommend Heart Checkup.” From the repository point of view, the
rule should look like:
RuleId: 11
BelongsTo: Transaction 10
RuleText: gender is male and age is above 45
The solution is to add one extra column for each
implementation environment. In this case, it was simply SQL, so only one extra
column was needed. That column is populated after the first cycle of analysis
by the software developer based on the text of the rule:
ExecutableRule: emp.gender=’Male’ AND emp.age>=45
This approach increases the chances of human error but
significantly decreases the complexity of the system. The generic validation
routine is fairly simple:
create or replace function f_validate (pin_pk_id number,
pin_pk_column_cd varchar2,
pin_class_cd varchar2,
pin_trans_id number)
return boolean
is
cursor c1 is
select ExecutableRuleTx
from ste_rule
where trans_id =
pin_trans_id;
v_out_nr number;
v_rule_tx
varchar2(2000);
v_hasfailedrule_b
boolean:=false;
begin
open c1
loop
fetch c1 into
v_rule_tx;
exit when
c1%notfound or v_hasfailedrule_b=true;
execute immediate
'select count(*) from '||pin_class_cd||
'
where '||pin_pk_column_cd||'='||pin_pk_id||
'
and ('|| v_rule_tx ||')' into v_out_nr;
if v_out_nr=0 then
v_hasfailedrule_b:=true;
end if;
end loop;
close c1;
return
v_hasfailedrule_b;
exception
when others then
if c1%isopen=true
then
close c1;
end if;
return false;
end;
This example involves passing a table into the function
where the object is stored. A primary key and column to store the primary key
allow the system to uniquely identify the desired object. Also this code passes
the transaction to be moved in order to be able to select the applicable rules.
But since that rule has already been built for PL/SQL, the system is immediately
ready to query the result.
II. Event-Condition-Action Generators
The next example is significantly more complex. Here, the relational
and object-oriented worlds start to drift towards each other. An Event-Condition-Action
architecture was used at Dulcian and provides the following illustration:
·
A set of UI elements exists, for example, button1
(named “Set Default End Date”), textField1 (contains start date), textField2
(contains end date)
·
Elements may have events associated with them,
i.e. button1 is associated with the event “Press.”
·
Events may have associated conditions such as “end
date is null.”
·
If the condition is satisfied, the event has an associated
set of actions:
- Set
end date equal to start date + one month both on the screen and in the
database.
- Disable
the end date field.
This structure looks perfect, but how can it be determined
what should be done to which elements, especially on the database side? The solution
was to divide the task into several parts:
1.
Notify the database about the event:
Begin
Garp.main(module=>’MainApp’,block=>’Buttons’,item=>’button1’,event=>’Press’,current_object_id=>100);
End;
2.
Generate a list of appropriate actions:
procedure p_addAction
is
cursor c1
is
select e.*
from ar$action e,
ar$event e,
ar$object o
where r.id=e.id
and e.id=r.id
and o.module_tx=pin_module
and o.block_tx=pin_block_tx and o.item_tx=pin_item_tx
and e.event_tx = pin_event_tx;
v_checkRules boolean;
begin
for c in c1 loop
if f_checkRules (e.action_id) =
true
then
insert into ar$ExecuteAction
(...)
values(...);
end if;
end loop;
end;
3.
Check all corresponding rules for each action:
function f_checkRule
(pin_astion_id number)
cursor c1
is
select r.condition_tx,
r.executable_rule_tx, r.Class_CD
from ar$rule r
where action_id = pin_action_id;
v_rec c1%rowtype;
v_hasfailedrule_b boolean:=false;
v_out_nr number;
begin
open c1;
loop
fetch c1 into v_rec;
exit when c1%notfound or v_hasfailedrule_b=true;
if c.Class_cd = 'NOCLASS'
then
execute immediate 'select count(*) from dual where
('|| v_rec.executable_rule_tx ||')' into v_out_nr;
else
execute immediate 'select count(*) from
'||c.Class_CD||
' where
'||pin_pk_column_cd||'='||pin_source_object_id||
' and ('||
v_rec.executable_rule_tx ||')' into v_out_nr;
end if;
if v_out_nr=0 then
v_hasfailedrule_b:=true;
end if;
end loop;
close c1;
return v_hasfailedrule_b;
exception
when others then
if c1%isopen=true then
close c1;
end if;
return false;
end;
4.
Retrieve the list of actions that correspond to the event
and process it on the client side:
Select module, block, item, action, ...
From ar$ExecuteAction
Now the set of rows
will be transformed in the set of commands in the front-end. It is out of scope
in this paper to discuss the last part, but the core idea of such
transformation is crucial from the database point of view. At this point, there
is an option to manage not just data rules, but virtually any possible rule
(including visual ones) from the repository.
III. Communication
Interface Generators (XML)
Another interesting implementation of real-time generators occurred
with a front-end environment that was working against XML-based forms. The problem was that the set of APIs only
worked with specially formatted XML documents. In this case, it was
significantly easier to create a two-way parser rather than expect changes in
the API. Since these documents were
specially formatted, it was not possible to use internal XML parsers from the
database.
The solution was fairly simple:
1.
Map existing data into the appropriate XML tags
(discussed later)
2.
Generate an XML-document procedurally as a regular text
document from the maps
3.
Store the original CLOB in the table
4.
Query that table from the client side
5.
Convert the string into an XML-document
6.
Apply the required APIs
The reverse order applied when users were saving their
changes:
- Compare
the modified XML-document with the master copy
- Store
the differences as CLOBs in the table
- Map
XML tags to real columns and set their values
Maps will be discussed later, but there are challenges in
the manual creation of XML. For example, some characters are special for XML
(“>”,”<”,”&”,” %”) but others could be special in the database
(single quotes, characters from different languages). A converter of strings
into the XML-compatible format may be useful:
function f_validateStringForXML
(in_string_tx varchar2) return varchar2 is
v_out_string_tx varchar2(4000);
v_temp_string_tx varchar2(4000);
begin
v_out_string_tx:= replace (in_string_tx,'>',' greater
than ');
v_out_string_tx:= replace (v_out_string_tx,'<',' less
than ');
v_out_string_tx:= replace (v_out_string_tx,'&',' and
');
v_out_string_tx:= replace (v_out_string_tx,'%',' pcnt ');
v_temp_string_tx:=translate(v_out_string_tx,'
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789+-/|\=,.;:!?()[]{}~@#$^_%''"'||chr(9)||chr(10)||chr(13),'|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||');
v_temp_string_tx:=replace (v_temp_string_tx,'|');
v_out_string_tx:=translate(v_out_string_tx,'a'||v_temp_string_tx,'a');
return v_out_string_tx;
end;
B. Compilers
It is common knowledge that compiled code results in the
best possible performance. In the world of business rules, the term “compiled”
means that some physical objects (tables, procedures, files etc.) will be
created. These objects will fully (or as much as possible) represent the set of
business rules, so that the executable code will need to access the repository
fewer times.
I. Data models
Data models also represent structural business rules. There
are tools that allow you to generate database objects directly from the
repository, but in the business rule environment this involves much more than
simply generating a bunch of tables. Many of these structural rules such as “field
<gender>can only have values male/female” may be represented as foreign
keys from the EMP table to the reference
table. The following item types can be generated:
- Tables
- Constraints
- Views
- Triggers
both on tables and views
- Packages
Also, in the later versions of the Oracle database (9i and up) it is possible to rename items
in real-time (columns, tables etc), making it possible to implement business
rule changes on the fly.
Therefore, there are two main tasks to accomplish: create
original code and maintain changes to the repository. In our opinion, the second
task is just as important as the first one. Although the creation of Version 1-prototypes
is useful, the real core of rule-based systems is maintaining a strict
one-to-one relationship between the definition of a business rule and its
implementation. If we trust developers to implement ongoing changes, there may
be 10 different nuances for 10 different people. Using the generator means that
you always know what is going on in the database. For example, the following
code shows how the database will behave if the class is renamed. Note the
changes not only to the table that represents the class, but also the primary
key column, which is always ClassCode||’_OID’):
procedure setTableName(in_class_id number,in_oldtablename_tx
varchar2,
in_oldclasscode_tx varchar2) is
v_ddl_tx varchar2(2000);
begin
v_ddl_tx:='rename '||in_oldtablename_tx||'
to '||brx$qry.gettablename(in_class_id);
execute immediate
v_ddl_tx;
v_ddl_tx:='alter table
'||brx$qry.gettablename(in_class_id)||' rename column '
||in_oldclasscode_tx||brxv$pkg.getdefaultseperator
||'OID to
'||uml$rep.getclasscode(in_class_id)||
brxv$pkg.getdefaultseperator||'OID';
execute immediate
v_ddl_tx;
end;
Another major challenge lies in the somewhat limited
notation of ERDs. UML notation includes all of the features of ERDs along with
a large number of extensions. The problem is that Oracle is a still relational database. So how can you
use UML to your advantage? Your solution does not need to be perfect. For
rule-based systems, there should not be any ambiguity about the implementation.
For example, one of the most popular tasks, which has been hand-coded by
hundreds of developers is maintaining historical records on a class. In some
cases, very special implementations might be needed, but for the majority of
situations, the following should be enough:
1.
Add two new columns to the table: start_dt and end_dt
2.
Add three new columns to the view: start_dt, end_dt and
active_yn
3.
If end_dt is populated, then the object is considered
inactivated.
4.
If end_dt is set to Null, then the object is reactivated.
5.
Add Before-(Insert, Update, Delete) to the view to prevent
any activity on the object if it is inactivated except for update of end_dt
As an example, the following procedure is fired on the
BEFORE UPDATE trigger and performs all of the necessary validation and modifications
mentioned above:
procedure historyBU(in_oldStart_dt in Date,
in_oldEnd_dt in Date,
in_oldActive_yn in varchar2,
io_newStart_dt in out Date,
io_newEnd_dt
in out Date,
io_newActive_yn in out varchar2,
in_class_id number
) is
begin
if in_oldActive_Yn='N'
and io_newActive_yn='N' then
uml_error.raiseengineexception(115,'The object is inactive');
end if;
if in_oldActive_yn='Y'
and io_newActive_yn='N'
and io_newEnd_dt is null
then
sec$current.caninactivate(in_class_id);
io_newEnd_dt:=sysdate;
elsif in_oldActive_yn='N'
and io_newActive_yn='Y' then
sec$current.canreactivate(in_class_id);
io_newEnd_dt:=null;
--below there is no
change in active_yn
elsif in_oldEnd_dt is
null and io_newEnd_dt is not null then
sec$current.caninactivate(in_class_id);
io_newActive_yn:='N';
elsif in_oldEnd_dt is not
null and io_newEnd_dt is null then
sec$current.canreactivate(in_class_id);
io_newActive_yn:='Y';
end if;
--if modifing start date
if
in_oldStart_dt!=io_newStart_dt
and
io_newStart_Dt>sysdate then
uml_error.raiseengineexception(125,'Start Date must be less than
sysdate');
end if;
if io_newStart_dt is null
then
uml_error.raiseengineexception(219,'Start Date can''t be null');
end if;
if
io_newEnd_dt<io_newStart_dt then
uml_error.raiseengineexception(121,'Start Date must be less than End
Date');
end if;
if io_newActive_yn not in
('Y','N') then
uml_error.raiseengineexception(220,'Active indicator column valid values
are Y and N');
end if;
end;
II. Process models
A workflow can (and sometimes should) be represented as
generated code. From a purely performance-based perspective, the major drawback
of implementing advanced process flows is the large number of repository requests.
However, if all communications between different states of the flows could be
generated, not much else is required. The major problem is to determine which
portions of the rule(s) should be generated. Another critical factor is the
process flow notation to be used in the repository. At Dulcian, our own STE-notation
(extension of UML workflow model) was used. This notation includes the
following features.
- Classes
can have workflows consisting of states.
- States
can have events.
- States
are connected by transitions.
- Transitions
are initiated by special kinds of events.
- Transitions
can have rules. If a rule fails, then navigation via the transition is
impossible.
- Events
can have rules. If a rule fails, then the event is aborted.
- Events
and transitions can have corresponding tasks.
Another reason why this notation was used was that it better
supports the code generation concept in several ways:
- It
allows for a higher level of abstraction in the definition of a state (about 1 high-level state for
every 60 in a regular flowchart) and simplifies the code because of
the smaller number of logical structures involved (IF..THEN, LOOP, etc.)
- The
predefined, limited number of events significantly simplifies the code
because it precisely identifies the elements to be generated.
- Any
event (with rules and tasks) can be represented as a set of commands in
any procedural language.
- Any
transition (with rules and tasks) can be represented as a set of commands
inside of the initiating event code because the transition can be accessed
only via the activating event.
For example, Figure 3 shows a basic state with a number of
transitions.
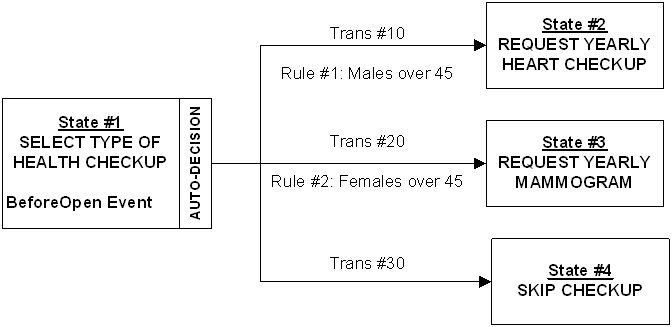
Figure 3. Representation of process state with several
transitions
The generated code is as follows:
procedure p_auto_1(SelfOID in Number) is
Begin
/*BeforeOpen*/
emp.setHealthValidationDt(sysdate);
/*:HealthValidatoinDt:=sysdate*/
if
(emp.getAge(selfOID)>=45 and emp.getGender(selfOID)='Male') then
/*(:Age >= 45 and
:Gender='Male')*/
ste$pkg.setState(SelfOID,2,10); -- object, state, transation
elsif
(emp.getAge(selfOID)>=45 and emp.getGender(selfOID)='Female') then
/*(:Age >= 45 and
:Gender='Female')*/
ste$pkg.setState(SelfOID,3,20); -- object, state, transation
elsif 1=1 then
/*No Rule*/
ste$pkg.setState(SelfOID,4,30);
else
raise
uml_error.e_ste_rule_failure;
end if;
End;
III. Maps
Earlier the term “maps” was mentioned with regard to the
system communicating in real-time with the XML-environment. The problem arose
when trying to work with the XML-based forms. Architecturally these forms were
exact copies of the paper forms, but the data model was significantly different
from what was shown on the screen. The challenge was in creating a mechanism to
map the stored data into XML tags. It was also mandatory to decrease the workload
on the client machines. As a result, the solution involved a full two-way
conversion of stored data into the precise data representation required for the
client code. A special mapping repository was created to carry out the
conversion. The simplified data model for this repository is shown in Figure 4.

Figure 4. Simplified Mapper Data Model
Originally DBàXML and XMLàDB maps were used. Later this architecture was extended to
support DBßàDB
maps. This provided an extremely powerful migration utility, because the generic
definition of the source and target elements enabled the creation of migration
maps between completely different data models of any level of complexity. MAP_READ
represents the source of the data. It could be just a query or an external
source such as an XML document). That data is transformed into the output set
that could be contained within any set of update statements to corresponding
columns or any other data representation (like an XML document).
Conclusions
Most portions of a business rule-based system involve some
type of code generator. By using these generators, in some cases the systems
created are more flexible; in others, the performance improvements are
significant. In all cases generators allow us to build systems “better/faster/cheaper.”
From a purely developer point of view,
there is one critical lesson to be learned, namely that it is important to think
through the architecture of the generator(s) from the very beginning of the project.
Here are a few of the factors to be taken into account:
- If
the data sources of routines are flexible, then generate queries.
- If
there is a possibility of communication with other language systems, then create
converters.
- If the
system must process a lot of data, then generate batch workflows.
Making sure that you ask the right questions from the
beginning goes a long way towards building a system that will meet, if not
exceed, the system requirements and remain flexible enough to cope with the
inevitable business rule changes down the road.
About the Author
Michael Rosenblum is a Development DBA at Dulcian, Inc. He is
responsible for system tuning and application architecture. He also supports
the Dulcian developers by writing complex PL/SQL routines and researching new
features. Michael is a frequent presenter at various regional and national
Oracle user group conferences. In his native Ukraine,
he received the scholarship of the President of Ukraine, a Masters Degree in
Information Systems, and a Diploma with Honors from the Kiev National
University of Economics.