Repository-Based J2EE Development
I. The Problem
The current web applications development product environment is clearly not ideal. It has many different components and is difficult to navigate. The resulting systems are also less robust than the client-server applications that were being built several years ago. The J2EE environment is evolving and changing so quickly that it is very difficult to keep up. Each year, the current thinking about web architecture evolves considerably. Two years ago, JavaServer Pages (JSPs) were the solution of choice, currently JSP/Struts are being used and next year, JavaServer Faces (JSFs) are likely to be the chosen alternative.
The industry standard, Enterprise JavaBeans (EJB), for middle tier development has been completely revamped with EJB3. Web Services and BPEL must now be taken into consideration along with a host of other new technologies. There is no agreed-upon industry standard for the right way to build J2EE-compliant web-based systems for no other reason than that these standards take months, if not years, to evolve and there continue to be major technology revisions every few months.
II. The Solution
One solution to this dilemma is to articulate the system in a technology-independent fashion. Every enterprise-level system includes thousands, if not tens of thousands of business rules. However, these rules fall into a small number of categories. It is possible to create a code generator to generate the appropriate code from these rule categories. The generator itself only requires a few thousand lines of code. The advantage of building systems using this approach is that when the technology changes, you only need to refactor the generator code to accommodate the new architecture.
This is not a new idea. CASE tools from many years ago were based on this same vision. So, why isn’t everyone using this approach? The answer is that it is very difficult to design the repository so that it is technology-independent, user-friendly, usable by normal developers, and understandable to users. It must also be robust enough to handle a reasonable number of applications and complex rule structures.
In practice, once the repository has been designed and built, writing the generator code is a surprisingly simple exercise. It may require weeks or even months to determine the user interface standards, appropriate technological implementation (e.g. the appropriate Struts flow diagram to generate). However, once these decisions have been made, building the code generator requires much less effort than initially creating, let alone maintaining, traditional applications. The reason for this is that the ratio of generator code to generated code may easily be 100:1 or more. As an example, in one project that the author worked on, the system generator required approximately 1000 lines of code. This generator was used to generate two versions of the system in both PL/SQL and Java, each of which contained 300,000 lines of code. In this one instance, it was possible to achieve a 600:1 payback on generator/generated code.
A. The Taxonomy
The taxonomy for describing the repository-based solution is as follows:
I. Logical Specification of a System
A. Object Rules
1. Structural
2. Process
3. Data Validation
B. User Interface (UI) Rules
1. Model
a. Structure
b. Binding to objects
2. View
a. Structure
b. Binding to model
c. Logic
d. Presentation
3. Controller
II. Physical Specification of a System
A. Persistence Layer
1. Objects
2. Code
B. Model
1. Objects
2. Code
C. View
1. Objects
2. Code
D. Controller
1. Objects
2. Code
B. Logical vs. Physical Specifications
Making the distinction between the logical and physical portions of the solution should raise few objections, but it is surprising to note how few product architectures (even ones with an expressed “business-rules based” philosophy) embrace this dichotomy.
The idea is the system can be specified in an implementation-independent way. Deciding what to do with this specification is then an independent step. This approach can be summed up in the motto: “The articulation of the rules is independent of the implementation of the rules.”
Most products ignore this idea and straddle the fence. As an example, the Oracle Application Development
Framework (ADF) Business Components (BC) architecture in the JDeveloper product
includes some user-friendly screens that allow you to articulate quite complex
business rules. These rules are then
represented either as XML files that are directly referenced by Java classes at
runtime or are themselves code generators.
This architecture makes it very difficult for someone building in
In the case of JDeveloper, ignoring the distinction between the logical and physical aspects of the system being built is appropriate. JDeveloper is an implementation tool. Its goal is to provide developers with quick and efficient ways to implement an architectural vision. With business rules-based products such as those mentioned above, this direct-to-code approach is inappropriate. One of the greatest advantages of a rules approach is that you are describing the system from the user’s perspective. It ought to then be possible to implement that description in a variety of different ways. As the technology evolves, it ought to be very easy to refactor the rules to support new technologies.
In the tools explicitly catering to the system architect,
this separation of logical and physical is implemented quite cleanly. Both Oracle Designer and
This division between the logical system specification and its implementation is not without problems. Having separate logical and physical layers requires that they be kept in synch. In systems that require maintaining two (or more) models, it is nearly impossible to keep them synchronized. This problem should be familiar to most database designers. Anyone using a tool that generates a data structure (such as Oracle Designer) is aware of the practical impossibility of keeping the model and database in synch. With Designer, the situation was more difficult since the tool supported both a logical ERD as well as a loosely coupled physical data model which was used to generate the actual physical database. Therefore with Designer, there are three representations of the database. When changes are required or errors discovered, they potentially must be made in all three places.
Using a waterfall methodology where the design progresses in an orderly fashion from logical development to physical implementation, this type of tool worked very well. However, once the system was in place, it was a very difficult architecture to maintain over time.
The problem arises from using the logical model to generate the implementation model and then allowing independent manipulation of the implementation model. There is nothing wrong with the idea of having both a logical and physical model, but trying to maintain multiple models is usually impractical.
The solution to the dilemma is to tightly couple the logical and implementation models. Instead of having independent logical and physical models, specify what is “logical” (implementation-independent) in the logical model and only specify “additional” (implementation-dependent) things in the implementation model. Only allow limited overriding of the algorithm used to generate the physical model and keep track of what was overridden so that element changes in the logical model can be updated in the physical model. This tight coupling of the system layers is an important concept to remember and enforce.
When logically specifying a system, the idea is to partition rules into those about objects that will be true for any representation of those objects and rules that are UI-dependent. Few existing products divide the rules in this way.
A. Object Rules
Object-level rules are where most of the design of the system takes place. This idea should be the core of our thinking about application development. Traditionally business rules about the objects are not even captured coherently let alone coded so they are clearly attached to the objects.
Logically, object rules are not a difficult concept to grasp. For example, if lastName_tx is a required attribute of the Employee class, then any user interface that supports inserting or editing that object should properly enforce that rule. Therefore, it should not be incumbent upon the system designer to specify that the attribute is required at the UI level. All that should be necessary is an indication that this text box is an editable representation of the attribute so that the object level rules (length, required, textual validations) apply.
The newer and more complex aspect to the concept of object rules is that their inheritance should be automatic. In addition, whenever possible rules should be specified at the object level and be inherited at the UI level.
Rules associated with objects usually comprise a large portion of the total system rules. Many people think of object rules as only contained in the data model. While it is true that object rules will define the data structure of the database, these rules can specify much more than what is contained in a traditional ERD. For example, the logical process flow for handling an object such a purchase order can be defined at the object level. The process should also be independent of any particular representation in the user interface. Data validation rules such as “any contract actions should take place between the start date and end date of the associated contract” should be articulated with the object so that any representation would conform to the rule.
B. User Interface (UI) Rules
If rules are placed at the object level, why are additional
rules needed at the user interface level? It is possible to generate an entire
default user interface based solely upon knowledge of the associated objects. However,
what is generated will not be particularly user-friendly. There are additional rules
that are concerned more with the needs of the user that are not properly
associated with system objects at all. For example, determining which
attributes will be displayed in what positions on the screen, what areas of the
screen are automatically populated when the screen opens, whether or not rules
are validated when tabbing out of
C. Where should the rules be defined?
This division between object rules and UI rules is not
always clear cut. Occasionally, there are rules encountered that could be placed
in either category. For example, in an address object with COUNTRY and POSTAL
CODE attributes, at the object level, the COUNTRY and POSTAL CODE should be
consistent. However, in practice, changing the COUNTRY from
If UI rules are attached to the objects themselves and overridden in the representation of the object, full object-oriented (OO) thinking must be used in designing the repository. This renders the repository more difficult to use, especially for non-IT professionals. If a rule structure is too complex for users to understand, there is little reason to include it in the repository.
It is still a good idea to define rules that are universal across all representations of an object at the object level. Only additional UI-specific rules should be defined at the UI level. Most of the rules required to define an application occur at the object level. In practice, the division is approximately 80% object rules and 20% UI rules.
D. Object Rule Types
Object Rules can be subdivided into Structural, Process and Data Validation rules. It is important to remember that these rules by their nature do not divide into these three classifications. These are three different and arbitrary ways to describe object rules. For any given rule, it is usually most convenient to articulate it using one particular mechanism, but most rules can be articulated using more than one mechanism.
1. Structural Rules
Structural rules describe the static nature of the objects in the system. What are the objects of interest? What are the attributes associated with them? This is the kind of information that is traditionally captured in ERDs although in recent years, UML class diagrams have become more widely used for diagramming systems.
UML Class diagrams (with some extensions) are somewhat better suited for data modeling than ERDs. ERD proponents argue that UML is an implementation tool and that cannot be used for logical modeling. UML proponents argue that ERDs are too limited and do not support inheritance well enough. This debate is beyond the scope of this paper but the choice of diagramming syntax is of far less importance than deciding what is to be captured.
Data modeling has traditionally only been concerned with capturing the information required to generate the tables, columns and constraints for the DBMS. Structural rules include a much broader range of information than that limited scope. Structural rules should include the following areas not traditionally included in data modeling:
1) Derived attributes
2) Objects defined using other objects (for example, to generate database views)
3) Audit, security, and history requirements
4) Default object display
5) Triggering events based on Insert, Update, and Deletion of objects or attributes
The idea is to partition all of the rules required to specify a system, and not simply identify the rules necessary to generate the database. Focusing on database generation rather than on the structure of the objects is a primary reason for the limitation of CASE tools such as Oracle Designer. Rather than thinking about capturing rules of a specific type (i.e. structural), CASE tools focused on the purpose (i.e. generating a database), hence the tools never evolved to full system specification tools.
For the structural rules area of the repository, imagine a standard UML class diagram meta-model as shown in Figure 1. Of course the real model would be more complex, but for the purposes of this paper, showing the key classes is sufficient.
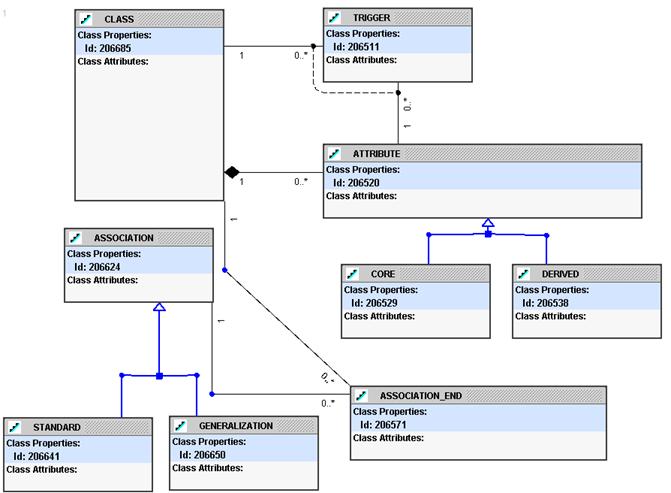
Figure
1: UML Class Diagram Meta-Model
NOTE: The only part of the model that may seem odd is having “association end” as its own class. This allows generalizations to have one head end class and multiple end classes.
2. Process Rules
Process rules define the process flow of an object from one state to another. A particular object may have states associated with different aspects of the object. For example, a person may simultaneously have a physical health as well as an economic health. One could define independent process flows for each aspect.
Process rules should be described using some type of flowchart or process flow rather than a declarative mechanism. There are simply too many rules associated with an object to be able to manage without dividing the object flow into states. If process rules are specified using a declarative mechanism, you end up having thousands (or even tens of thousands) of rules. These rules interact, may cancel each other out, and are impossible to manage.
Traditional State Transition Engine (STE) diagrams or flowcharts are similarly hard to manage. You might remember university classes in programming where you were forced to create flowcharts to document your programming assignments. You always wrote the code first and the flowchart afterward. The flowchart for a simple 200-line program had 60-80 little boxes on it and the flowchart was harder to read than the program code itself.
The solution to making an
The formal structure used is to add the idea of an “event” on a state (similar to the idea of a database trigger on a table). When the event is triggered, actions can be executed. Rules can be attached to an event to prevent it from occurring (for example security to prevent an object from being opened).
States are associated with a class of object. Process flows are not independent things. The process flow defines the allowable states for a particular class of objects.
The high-level process flow repository is shown in Figure 2.
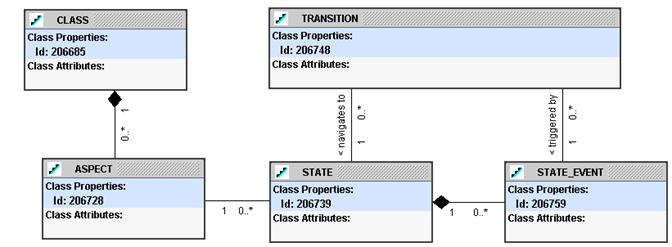
Figure 2: Process Flow Repository
3. Data Validation Rules
Data validation is a complex topic in its own right. A system can easily have hundreds of data validation rules. These rules may always need to be enforced or only contingently enforced based upon some condition or the state of the object. The rules may only require looking at the object being validated or accessing objects in other classes. Rule failure may only trigger a user warning or may prevent data modification entirely.
The difficulty is in coming up with a grammar to help specify the rules. Natural language is not precise enough and code is too hard to read. The solution is to place the rules at the object level but support an Object Constraint Language (OCL)-like syntax that allows you to validate across classes. For example, the rule to say that a department must have at least one employee (in the standard emp/dept 1-many model) would be written as:
:_child.emp.count >= 1
This grammar can be easily extended to support 99% of all rules encountered.
Validation rules are often only contingently required. Therefore, these rules can be invoked at the object state level and may be contingently executed based upon some condition. The high level model to support the data validation repository is shown in Figure 3.

Figure 3: Data Validation Repository Model
E. User Interface (UI) Rule Types
Once the object rules are collected, there are some additional rules required to specify the UI. For the purposes of this discussion, the UI rules will be kept to a minimum so that rules described at the object level will not be repeated at the UI level.
The model-view-controller (MVC) pattern architecture itself will not be discussed here nor will the decision to use it be defended. However, the author’s perspective on MVC may be slightly different than the industry standard in that it is viewed as a logical design pattern, and not simply a way to write code. The goal here is to define the application independent of any technology or implementation considerations.
1. Model Layer
The model portion of the logical UI rules is not difficult to specify. There is already so much information at the object level that little extra information is required at the UI level. Classes, attributes and associations have already been defined at the object level. As a result, the only requirement at the UI level is to select a subset of objects (classes, attributes, associations) from the object level for use in the UI specification. This approach runs counter to the way in which most systems are built. Most tools specializing in model development support very sophisticated object specification in the model portion of the UI. This approach does not preclude a “thick” UI model level for implementation; it merely implies that the structure of the UI model should properly be defined at the object-level.
Using this approach means that the structural rules at the object level will be quite sophisticated, requiring not only standard views, but also views that are dynamically altered or generated based on the values of some passed parameters. All that remains for the UI model specification is to point to existing structural object specifications. The model to support this is shown in Figure 4.
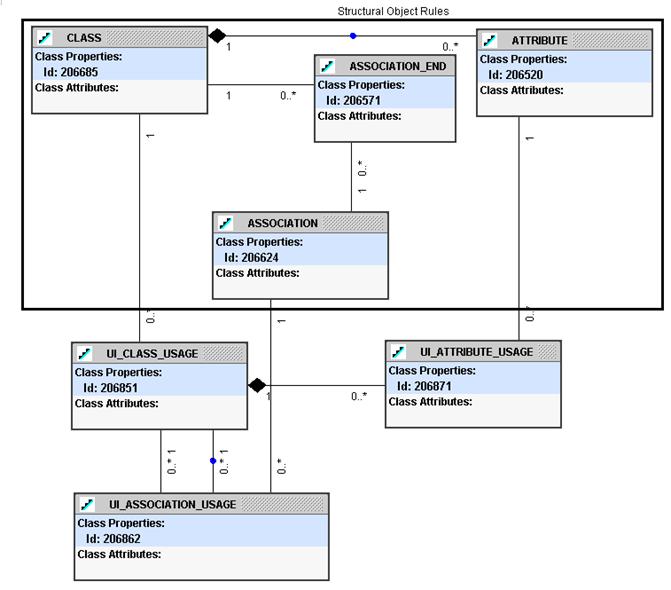
Figure 4: UI Model Specification
2. View Layer
The rules in the view layer of the logical UI are themselves divided into structural (what are the elements and how are they grouped), logical (what happens when a screen opens, or a button is pressed), and presentation (how and where the elements are displayed).
The view layer structural rules are very simple. They define the UI elements (fields, buttons, etc.) and how they are grouped and bound to the UI model.
On the other hand, the view layer logical rules are quite
complex. A full Event-Condition-Action (
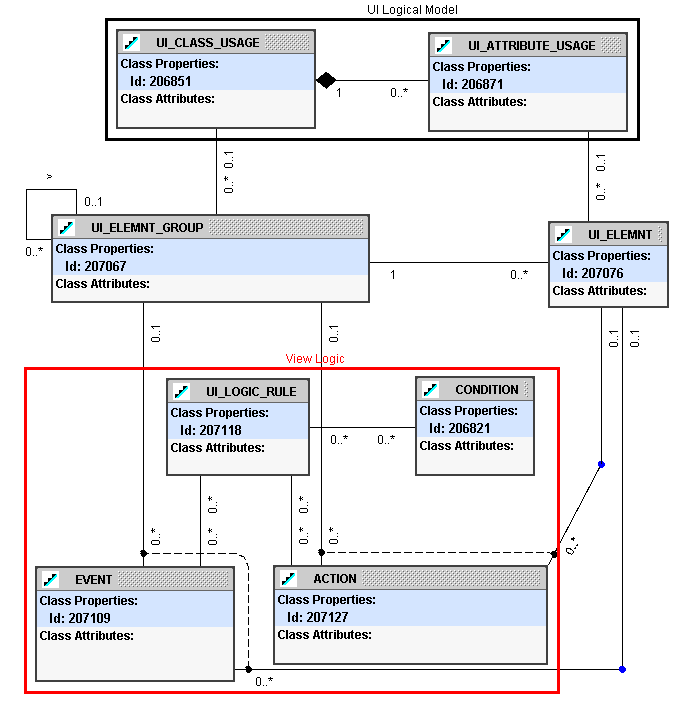
Figure 5:
Presentation rules are simply attributes of UI Element Group and UI Element. The tricky part here is that different products use very different methods to describe layout presentation. The Oracle Developer tool used X and Y position, whereas HTML uses tags that automatically position themselves on the screen. Trying to come up with a technology-independent way to describe layout is not a problem that is currently well under control.
3. Controller Layer
The real strength of the MVC design pattern is the Controller
layer. This layer can be partitioned
into rules controlling screen navigation and what happens during these screen
transitions. The Struts controller should not be used to logically define
rules. This is too restrictive an
implementation and would force a redesign if/when JavaServer Faces become the
standard. The Controller layer is a natural place for using the same type of
By using a technology-independent way of describing page flow, you can generate the system to Struts, JSFs, or any other platform.
4. UI Shortcuts
There are standard UI structures that you should not have to
build over and over again. You can define system elements such as browse screens
that only require
For example, in the browse screen, the only elements that must be specified are:
1) Fields that you want to query by (and how they appear)
2) Fields in the display block (and how they will appear)
The rest is automatic. This approach allows you to build the user interface very quickly. You simply specify the browse screen for a particular class, point and click the desired query by attributes and display and out pops the application.
The model for specifying a browse screen is shown in Figure 6.

Figure 6: Browse screen model
As shown in Figure 6, the repository is very simple. Since you know the object class on which to
base the browse screen, all that is left is to specify
IV. Physical Specification of a System
Once a system has been logically specified, you need to specify the physical structure of the generated code. This can be done using a standard meta-model that conforms to the way in which the system will be built. The appropriate model will vary depending upon the technology. (That discussion is beyond the scope of this paper.)
Generated elements will be linked to their generating counterparts. It is good design practice to limit how much overriding of generated elements will be allowed. Allowing developers to override table and column names so that they are different from class and attribute names would make the object structural class diagram useless and should be avoided.
Most of the work of generating the final system which involves designing the repository and writing the generators is not difficult. The hard part is deciding on the appropriate UI standards and the best way to build the generated system. There are many decisions to make. The following sections describe some of the most important ones to consider.
A. Use a Thick Database Approach
The author prefers to keep the applications as “thin” as possible and generate as much as possible in the database. This means generating separate views for each screen and placing code in the database whenever possible.
No object rules will ever be implemented outside of the database. Structural rules generate to tables, views (perhaps with INSTEAD OF triggers) and packages. Even “getters” and “setters” that OO developers might want to exploit are generated as packages. Process logic is generated as PL/SQL packages and dynamic views.
All UI logic is controlled within the database. The application will notify the database that an event has occurred (e.g. a button is pressed) and the database will return a list of actions for the application to execute.
Even browse screens will have query criteria based on an INSTEAD OF trigger view. Updating the view will automatically rebuild an object collection (using the PL/SQL in the INSTEAD OF trigger) that will be returned to the application containing what is to be displayed.
Using a thick database/thin application approach means that moving to a different UI architecture (e.g. JSP/Struts to JavaServer Faces) will not require rewriting a large portion of the generators.
B. Use ADF BC
Usage of Oracle’s Application Development Framework -
Business Components (
C. Limit the UI Design Options
Set your UI standard and stick to it. Do not allow developers more than a small handful of options when specifying the UI.
D. Use JSP/Struts
For most applications, client/server architecture is no longer necessary. JavaServer Faces are not ready for prime time. Using the industry standard JSP/Struts provides the robustness and capabilities necessary to build a production system.
E. Avoid Post-Generation Modification
Make your architecture rich enough so that you do not need to modify the generated applications.
V. Overview of the Generated Application
The generated application consists of the following parts:
· one user login page
· one main menu page
· a browse page for each class in the application
· an edit page for each class in the application
·
a State Transition Engine (
On the Login page, the user name and passwords are defined in a separate table. The generated applications verify the login information using these definitions.
The main menu page contains links to the browse page of each class involved in the application.
An example of a browse page is shown in Figure 7.
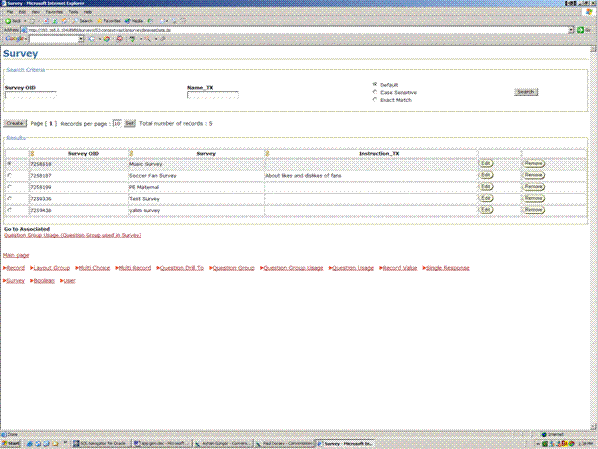
Figure 7: Sample Browse Page
The Browse page consists of four sections:
1. Search Criteria: This section includes search fields that are generated according to the domain of the column with which they are associated. For example, Value Lists are generated as combo boxes.
2. Results: This section displays the query results. It also includes a navigation bar to quickly locate the desired rows.
3. Associations: This section shows links to the master and detail classes. It is generated using the associations specified in the UML Data Model. For example, in a standard Department/Employees application, there would be an Emp link in the Dept browse screen. Clicking this link brings you to the Emp browse screen and only shows the employees associated with the active Department in the Dept browse screen.
4. Menu: This section includes links to all classes in the application.
A sample Edit screen is shown in Figure 8.

Figure 8:
Sample Edit Screen
Fields on the
Edit screen appear or disappear depending upon the security settings of the user
who is logged in. The fields can be editable, display-only or not show at all. The
size of the fields is based on the domain settings of the associated column in
the object model.
A. The Generator
Once the logical application is specified, the user calls a database procedure that starts the application generation process.
The generator is written in PL/SQL. It consists of about 18,000 lines of code. Its output is a JDeveloper workspace folder in the operating system. Once the generation is complete, the generated workspace is zipped and the user downloads the zip file onto his/her local machine. At this point the workspace is ready to use.
The generated workspace uses a small custom tag library (paging functionality used in the browse page) and a code library (for security).
B. The Generated Application
The generated application is a standard JSP/Struts
application based on

Figure 9: Sample Struts Page Flow Diagram
The generated classes depend upon the function required. As an example, a generated search class as used in the Browse page is described here.
Search Functionality
This is integrated with the Search section in the Browse screen. The search section consists of fields (Search Elements) that are used to enter search criteria, a radio button for search method (Case sensitive, Exact match, Default) and a Search button. When the button is pressed, the SearchDA data action executes. The SearchDA is coupled with the corresponding doSearch method in the application module using the “published function” method. This coupling is done in the Struts-config.xml file.
The SearchDA passes the values (Search Elements) entered in the Search screen to the application module. The application module calls the corresponding search method in the generated Java Class. The search method processes the search elements and builds a “Search Criteria” object. A Search Criteria object consists of search elements which are used to build the WHERE clause and a View Object instance to apply the WHERE clause. The search Criteria object is then processed. During this processing, the WHERE clause string is constructed. Each Search Element is analyzed and, depending on the type of the column represented, the appropriate formatting is applied to the WHERE clause.
The WHERE clause is applied to the View Object and the view object query is executed returning the resulting rows of the search. At this point, the SearchDA data action completes and the Browse screen displays the results.
The following is an example of the generated code for the class called SrSurvey and the Struts Config. Xml tags:
<action path="/searchDA"
className="oracle.adf.controller.struts.actions.DataActionMapping"
type="view.SrSurveySearchDAAction" name="DataForm">
<set-property
property="modelReference"
value="srsurvey_browseDataUIModel"/>
<set-property
property="methodName"
value="srsurvey_browseDataUIModel.searchSrSurvey"/>
<set-property
property="resultLocation"
value="${requestScope.methodResult}"/>
<set-property
property="paramNames[0]"
value="${param.fSrSurvey_SrSurveyOid}"/>
<set-property
property="paramNames[1]"
value="${param.fSrSurvey_NameTx}"/>
<set-property
property="paramNames[2]"
value="${param.fSrSurvey_Case}"/>
<set-property
property="numParams" value="3"/>
<forward
name="success" path="/browseData.do"/>
</action>
Binding in the UI Model:
<DCControl
id="searchSrSurvey"
SubType="DCMethodAction"
Action="999"
RequiresUpdateModel="false"
DataControl="AppModuleDataControl"
InstanceName="AppModuleDataControl.dataProvider"
MethodName="searchSrSurvey"
ReturnName="AppModuleDataControl.methodResults.AppModuleDataControl_dataProvider_searchSrSurvey_result"
>
<Contents>
<NamedData
NDName="Arg0"
NDType="java.lang.String"
NDOption="2"
NDValue="%null%" >
</NamedData>
<NamedData
NDName="Arg1"
NDType="java.lang.String"
NDOption="2"
NDValue="%null%" >
</NamedData>
<NamedData
NDName="Arg2"
NDType="java.lang.String"
NDOption="2"
NDValue="%null%" >
</NamedData>
</Contents>
</DCControl>
Exposed method in the application module
public void
orderSrSurvey(String column, String type) {
Object _ret = this.riInvokeExportedMethod(this,
"orderSrSurvey", new String[] {"java.lang.String",
"java.lang.String"}, new Object[] {column, type});
return;
}
Method in the application module:
SrSurveyBrim SrSurveyb = new SrSurveyBrim();
public void searchSrSurvey( String SrSurveyOid, String NameTx, String searchCase) {
SrSurveyb.doSearch(getSrSurveyView1(), SrSurveyOid, NameTx, searchCase);
}
The Generated Java Class for Class SrSurvey
package com.dulcian.brim.bag;
import oracle.jbo.ViewObject;
public class SrSurveyBrim extends ClassBrim {
public SrSurveyBrim() {
}
SearchCriteria sc = new
SearchCriteria();
public void
doSearch(ViewObject vo, String
SrSurveyOid, String NameTx, String searchCase) {
sc.setCase(searchCase);
sc.setVO(vo);
sc.addElement("SR_SURVEY_OID", SrSurveyOid, null, OIDCOLUMN,
NUMBER, null);
sc.addElement("NAME_TX", NameTx, null, REGULARATTRIBUTE,
VARCHAR2, SIMPLE);
super.doSearch(sc);
}
}
Java Class ClassBrim.java. This class is the super class of all generated classes. It contains the search code that is shared by all of them.
package com.dulcian.brim.bag;
import java.util.Iterator;
import oracle.jbo.ViewObject;
public class ClassBrim {
public ClassBrim() {
}
public final String
NUMBER = "NUMBER";
public final String DATE
= "DATE";
public final String
VARCHAR2 = "VARCHAR2";
public final String
OIDCOLUMN = "OIDColumn";
public final String
MASTERDETAILRELATIONSHIP = "MasterDetailRelationship";
public final String
ASSOCIATIONCLASSEND = "AssociationClassEnd";
public final String
ASSOCIATIONCLASSHEAD = "AssociationClassHead";
public final
public final String
BESTATUS = "BEStatus";
public final String
REGULARATTRIBUTE = "RegularAttribute";
public final String
DERIVEDATTRIBUTE = "DerivedAttribute";
public final String
STARTDATE = "StartDate";
public final String
ENDDATE = "EndDate";
public final String
EXPIRATIONDATE = "ExpirationDate";
public final String
CLASSINDICATOR = "ClassIndicator";
public final String
ACTIVEINDICATOR = "ActiveIndicator";
public final String
VALUELIST = "Value List";
public final String
SIMPLE = "Simple";
public void
doSearch(SearchCriteria searchCriteria) {
String dateFormat = "MM/DD/YYYY";
String searchCase =
searchCriteria.getCase();
ViewObject vo =
searchCriteria.getVO();
String query =
"";
Iterator iter =
searchCriteria.getSearchCriteriaElements();
for(; iter.hasNext();)
{
SearchCriteriaElement
sce = (SearchCriteriaElement) iter.next();
if(sce.columnType !=
null && (sce.columnType.equals(OIDCOLUMN) || sce.columnType.
equals(MASTERDETAILRELATIONSHIP) ||
sce.columnType.equals(ASSOCIATIONCLASSEND)
||
sce.columnType.equals(ASSOCIATIONCLASSHEAD) || sce.columnType.equals(STATE)
||
sce.columnType.equals(CLASSINDICATOR))) {
if (sce.value1 !=
null && sce.value1.equals("NO_VALUE"))
query +=
sce.columnName + " IS NULL AND ";
else if(sce.value1
!= null && sce.value1.length() > 0)
query +=
sce.columnName + " = " + sce.value1 + " AND ";
} else
if(sce.domainType != null && sce.domainType.equals(VALUELIST)) {
if(sce.value1 !=
null && sce.value1.length() > 0 &&
!sce.value1.equals("-1"))
query += sce.columnName
+ " = '" + sce.value1 + "' AND ";
} else
if(sce.dataType != null && sce.dataType.equals(VARCHAR2)) {
if(sce.value1 !=
null && sce.value1.length() > 0) {
if(searchCase.equals("0"))
query +=
"UPPER(" + sce.columnName + ") LIKE UPPER('" + sce.value1 +
"%') AND ";
else
if(searchCase.equals("1"))
query +=
sce.columnName + " LIKE '" + sce.value1 + "%' AND ";
else
if(searchCase.equals("2"))
query +=
sce.columnName + " = '" + sce.value1 + "' AND ";
}
} else
if(sce.dataType != null && sce.dataType.equals(NUMBER)) {
if(sce.value1 !=
null && sce.value1.length() > 0) {
if(sce.value2 !=
null && sce.value2.length() > 0)
query +=
sce.columnName + " BETWEEN " + sce.value1 + " AND " +
sce.value2 + " AND ";
else
query +=
sce.columnName + " = " + sce.value1 + " AND ";
} else {
if(sce.value2 !=
null && sce.value2.length() > 0)
query +=
sce.columnName + " = " + sce.value2 + " AND ";
}
} else
if(sce.dataType != null && sce.dataType.equals(DATE)) {
if(sce.value1 !=
null && sce.value1.length() > 0) {
if(sce.value2 !=
null && sce.value2.length() > 0)
query +=
sce.columnName + " BETWEEN to_date('" + sce.value1 + "', '"
+ dateFormat
+
"') AND to_date('" + sce.value2 + "', '" + dateFormat +
"') AND ";
else
query +=
sce.columnName + " = to_date('" + sce.value1 + "', '" +
dateFormat + "') AND ";
} else {
if(sce.value2 !=
null && sce.value2.length() > 0)
query +=
sce.columnName + " = to_date('" + sce.value2 + "', '" +
dateFormat + "') AND ";
}
}
}
System.out.println(query);
if(!query.equals(""))
vo.setWhereClause(query.substring(0, query.length()-5));
else
vo.setWhereClause(null);
vo.setOrderByClause(null);
vo.executeQuery();
searchCriteria.getSearchCriteriaHashtable().clear();
}
}
Conclusions
It is possible to create a complete architecture to describe
and generate
About the Authors
Dr.
Yalim Gerger is the
founder and president of Gerger Consulting, representing Dulcian, Inc. in