
Dulcian was building the recruiting system for the United States Air Force Reserve. Most of the core user interface screens needed to be images of the paper forms that applicants fill out as part of enlisting in the Air Force. Those screens were mandated to be delivered using PureEdge Forms (now IBM Workflow Forms). This software was designed to support forms management. Users would fill out and sign forms then send them around in a workflow.
PureEdge was not really intended as an interface product for a database. However, they did have an interface that would read and write the data from a form as XML.
Many of the same data elements existed on multiple forms and there was a requirement to update overlapping information on one form and have it automatically update on all of the forms. The way we handled this was to read the data from a centralized database every time a form was opened. The data would be formatted as an XML document and then parsed on the client and loaded into the form. When the form was saved, the data would be extracted and formatted as an XML file and then sent to the database where it was parsed and the database updated as appropriate.
As you can imagine, the structure of the forms was very different from the structure of the database. There were also lots of forms (initially 40 when for the Reserve and now 200 to support for the entire Air Force. To generate the XML, each form may require up to 15,000 lines of code. Therefore, it was not practical to code all of this by hand. In addition, there are always new forms added over time, and the forms change so we really needed an efficient way to handle this task.
This is a classic ETL type of problem. Naturally we started looking at ETL mapping tools like Oracle Data Warehouse Builder and Informatica. We were not happy with either of these repositories because they did not approach the problem in the same way that I did. Traditional ETL tools tend to think in terms of populating one table at a time. When I build something like this by hand, I tend to think in terms of the whole object in a hierarchical structure that then writes to another (perhaps very different) hierarchical structure.
We ended up building our own object interaction repository to support this that looked something like the following:
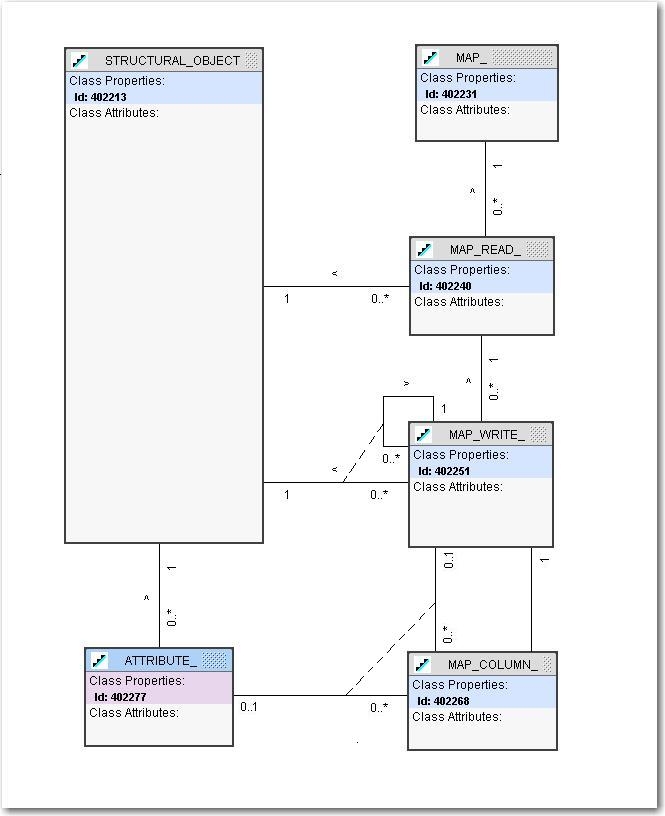
Object Interaction Repository Data Model
We then wrote a small generator (about 1000 lines of PL/SQL code) to generate the PL/SQL packages necessary to generate the XML for each form.
When we first used this object interaction repository for reading and writing XML, we generated about 50,000 lines of code. The productivity was wonderful. Two developers entering data were able to specify repository entries that generated about 3000 lines of code per day.
This was over 10 years ago. Since then, we have written lots of different generators that work on the same repository for different purposes:
- Generate XML for on-screen forms
- Generate XML for web services
- Generate views for UI screens
- Read XML, parse it and write into the database (we have a few different types of this generator)
- Build ETL scripts for batch database migration
- Read flat files
- Write flat files
- A Java version of one of the generators for a non-Oracle client
The object interaction repository itself has changed very little over time. We have added an attribute here and there when we needed to expand the capability or when using the Mapper for a different purpose, but it has been surprisingly stable.
We are still working on the Air Force Recruiting project which now includes over 1,000,000 lines of code generated by this single repository.
Where the Mapper has proven most useful is in generating code to support reading and writing of XML for web services. The XML required to support a web service can be completely different from how the data is stored in the database. Having a nice tool that lets you point and click your way through that transformation has saved us months of time each time we need to support a new web service.
Leave a Reply